
Let’s say your customer support agent asks for “billing issues”, and gets back technical support tickets, sales conversations with receipt issues, and billing disputes all mixed. This is the retrieval precision wall that teams hit once their agents accumulate weeks of interaction history: similarity search finds everything that’s semantically close for this customer but does not scope it to the relevant dimensions you actually need: issue type, status, or time.
Amazon Bedrock AgentCore Memory is a fully managed memory service that gives AI agents the ability to remember and recall information across conversations. It organizes agent memory records into namespaces that define isolated scopes like clients/client-123, so each entity’s data stays separate. You can read the blog on Organizing Agents’ memory at scale: Namespace design patterns in AgentCore Memory to understand more about namespace organization. As memories grow, relevant signals drown in semantically similar but contextually irrelevant results, and namespace scoping alone cannot separate them.
Metadata filtering closes this gap. You can now layer fine-grained, attribute-based filters on top of namespace isolation that helps in scoping retrieval by business dimensions like priority, department, or time range before similarity search runs. In our evaluations across a 151-question test set built on a long-term memory benchmark (LoCoMo-style multi-session conversation), it showed improvement. The overall question-answering (QA) accuracy rose from 40% to 64% with metadata filtering enabled across all question types. The gain concentrates in the subset of questions that depend on contextual boundaries, such as time-bounded lookups, priority-based filtering, or department-scoped searches. For those questions, accuracy jumped from 16% to 69%.
In this post, you will learn how metadata works across configuration, ingestion, and retrieval, explore enterprise use cases including multi-agent and multi-tenant architectures, and discover best practices for implementation.
Structuring the namespaces and metadata
AgentCore Memory uses namespaces to organize and isolate memories along primary entity boundaries. You scope retrieval to a specific namespace like clients/client-123/sessionABC or patients/patient-456, so your agent does not accidentally retrieve another client’s or patient’s data. Namespaces provide the foundational layer of separation. Read more about it in the blog on Namespace design patterns.

As deployments scale, semantic search within a namespace hits some limits. Consider a financial services agent with a namespace per client that has accumulated six months of interaction history. When a relationship manager asks the agent to recall “portfolio rebalancing discussions” for a specific client, the namespace correctly scopes the search for that client’s memories. But the results span different investment strategies, time periods, and priority levels within that client’s history. The agent can’t distinguish a high-priority rebalancing conversation from last week from a routine inquiry three months ago. The information is semantically similar, but the context is entirely different.
Multi-tenant environments illustrate the layering clearly. Namespaces already give you full data separation between tenants. Within each tenant’s namespace, your IT helpdesk agents still need to filter ticket type before searching for resolution patterns. Namespaces are the logical separation on the who. Metadata filtering handles the sub-grouping within those boundaries: the category, resolution status, date, priority, and tags.
Metadata in AgentCore Memory
Metadata in AgentCore Memory operates across both short-term and long-term memory, following a three-phase lifecycle: configuration, ingestion, and retrieval. The following sections walk through how metadata works at each memory layer, starting with short-term memory and then diving into the full three-phase lifecycle for long-term memory.
Metadata in short-term memory
At the short-term memory layer, you attach string-based key-value pairs to events, tagging interactions with contextual information that isn’t part of the conversation itself but is critical for later retrieval.
Short-term memory metadata supports string-based key-value pairs on events, that can be used for filtering. These tags carry forward into long-term memory during extraction and consolidation, where they become filterable dimensions.
Metadata in long-term memory
Long-term memory is where metadata delivers its full impact. Three phases described below give you precise control over how structured context is declared, propagated, and queried. In short, you declare which keys matter at configuration time. Attach or let the model infer their values during ingestion, and filter on them at retrieval. When several events in a session carry the same key, AgentCore Memory merges them into one value using the resolution behavior you defined in the llmExtractionInstruction.
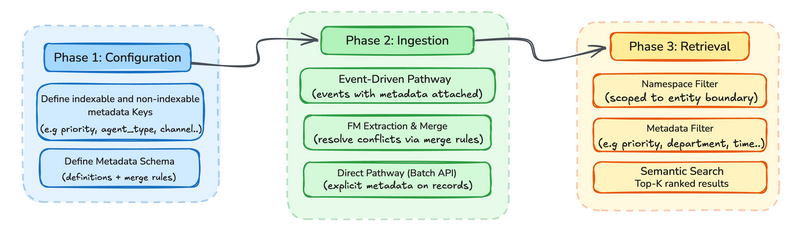
Phase 1: Configuration
When you create a memory resource, you declare which metadata keys to index for fast filtering and retrieval across memory records. Defining a metadata schema on each memory strategy that instructs AgentCore Memory how to extract and resolve metadata values. Indexed keys are stored in a format optimized for query filtering, while non-indexed keys are stored alongside memory records for informational purposes.
The following creates a customer support memory resource with metadata configuration:
Each schema entry’s extractionConfig guides the large language model (LLM) during metadata extraction. The definition field describes what the field represents, while llmExtractionInstruction provides additional extraction guidance and conflict resolution behavior. The built-in LATEST_VALUE operation provides recency-based resolution, while custom natural language instructions handle domain-specific logic. The optional validation field constrains the extracted values, such as allowedValues for STRING and STRINGLIST, maxItems for STRINGLIST, or min-max for NUMBER. This maintains consistent values for downstream filtering. Notice (in the preceding code sample) that sentiment is defined in the schema but not declared as an indexed key. Thus, the LLM will derive its value purely from conversation content and populate it on extracted records, but it cannot be used in metadata filter expressions.
Notice that ticket_id is declared as an indexed key at the memory level but not included in the strategy’s memoryRecordSchema. This key will not be populated on extracted memory records. Only keys defined in the strategy’s memoryRecordSchema appear on records after extraction. Indexed keys absent from the schema are omitted, even if matching values exist on the originating events. If you need a key to appear on extracted records, it must have a schema entry.
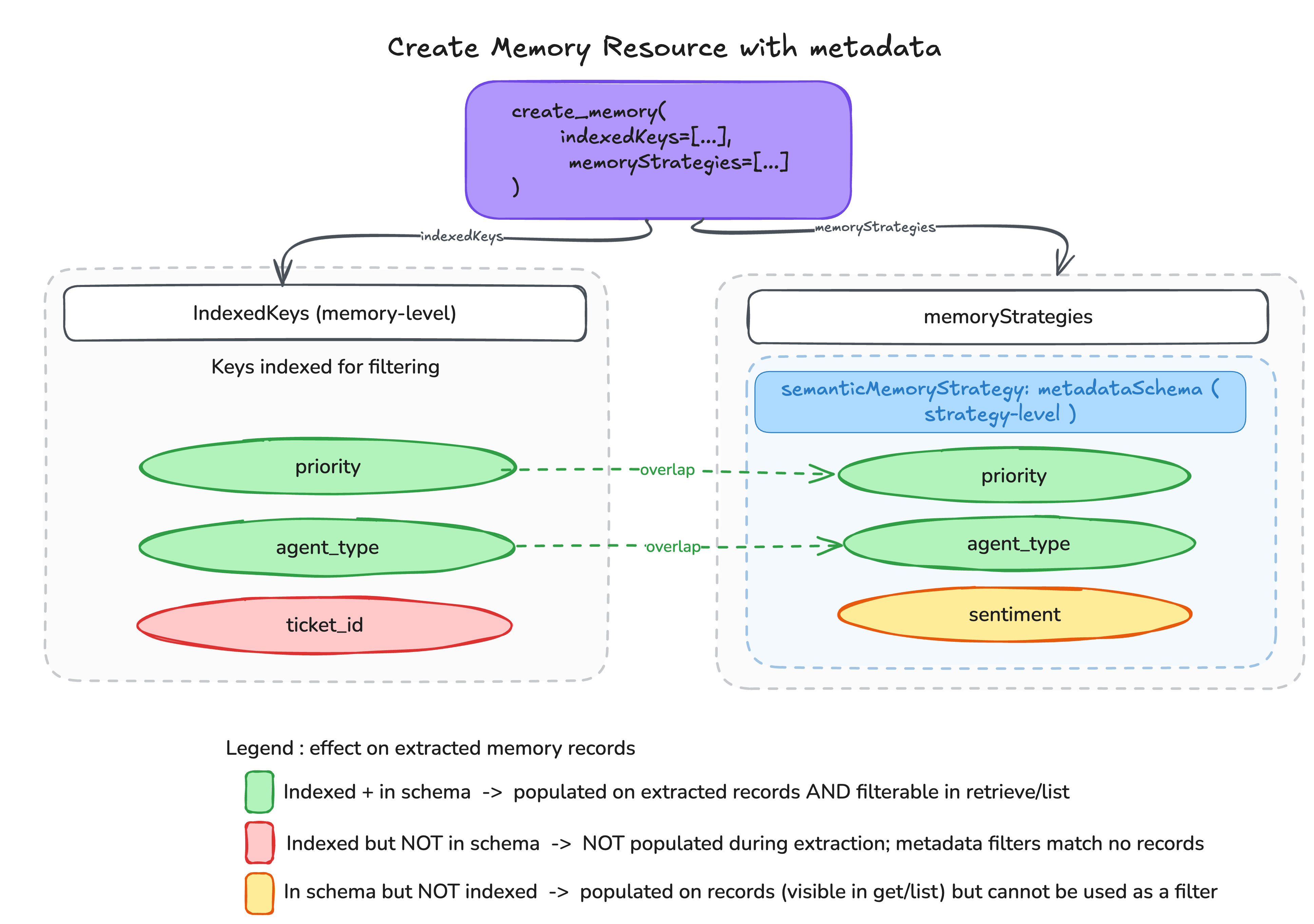
You can read more about the configuration constraints in the AgentCore Memory documentation. Apart from the configured metadata keys, temporal filtering (to account for memory decay, if relevant) is available through system-generated dateTimeValue fields, x-amz-agentcore-memory-createdAt and x-amz-agentcore-memory-updatedAt, which support BEFORE and AFTER operators without requiring you to declare datetime indexed keys.
Strictly-consistent metadata for known values
Some metadata keys are organizational classifiers like department, compliance_level, or interaction_type. These carry values the calling application already knows at event creation time, and they must land on the resulting memory records exactly as supplied. LLM extraction introduces variability for these keys: the same conversation can produce “eng” on one record and “Engineering” on another, and a value provided on the event may be re-inferred during extraction. AgentCore Memory addresses this with the STRICTLY_CONSISTENT extraction type, an option to the LLM_INFERRED extraction type. When a key is configured this way, the value supplied on the event propagates unchanged through extraction and consolidation, and the LLM isn’t consulted for that key.
STRICTLY_CONSISTENT keys do more than skip inference. They partition extraction. Events sharing the same values are always extracted together and isolated from events with different values, so there is no ambiguity about which value belongs on a record.
This isolation also governs consolidation. Records produced from one set of deterministic values are only ever consolidated with records sharing those same values. A record carrying department: "billing" will not merge with one carrying department: "engineering", regardless of how semantically similar their content might be.
Consider a support session where a customer’s issue spans multiple departments:
Without deterministic isolation, all three events would be extracted together. The LLM might assign department: "billing", department: "engineering", or even department: "account_management" to the resulting facts non-deterministically. With STRICTLY_CONSISTENT configured on department:
- Events 1 and 2 share the same deterministic values (
department=billing,priority=high) and are extracted together. The resulting memory records carry those exact values. - Event 3 has different deterministic values (
department=engineering,priority=high) and is extracted independently. Its records carrydepartment: "engineering"exactly.
A billing agent querying with department=billing retrieves only the facts about duplicate charges and the tier upgrade, not the provisioning bug detail from the engineering context. Consolidation respects the same separation: billing records and engineering records are not merged, even if their content is semantically related.
This makes deterministic keys ideal for compliance isolation (HIPAA vs. standard records do not co-mingle), organizational routing (department-scoped retrieval without cross-contamination), and any scenario where the calling application knows a value at event time and needs it preserved exactly on the resulting memories.
A key configured as STRICTLY_CONSISTENT must also be declared as an indexed key on the memory resource. Consolidation scopes by metadata filters on indexed keys, and that scoping is what keeps records with different deterministic values from merging. Events that are missing values for a deterministic metadata key are still processed, and the key is simply absent on the resulting record.
AgentCore Memory supports up to three STRICTLY_CONSISTENT keys per strategy. Each one of these keys consumes one of the ten indexed-key slots on the memory resource, and indexed keys can’t be removed once added. Reserve slots ahead of time if you plan to use this feature.
Phase 2: Ingestion
Once you’ve configured your metadata schema, the next step is ingesting data with metadata attached. Metadata enters the system through two pathways. The event-driven pathway attaches metadata to events, and AgentCore Memory automatically propagates it through extraction and consolidation (based on extraction instructions) into long-term memory records:
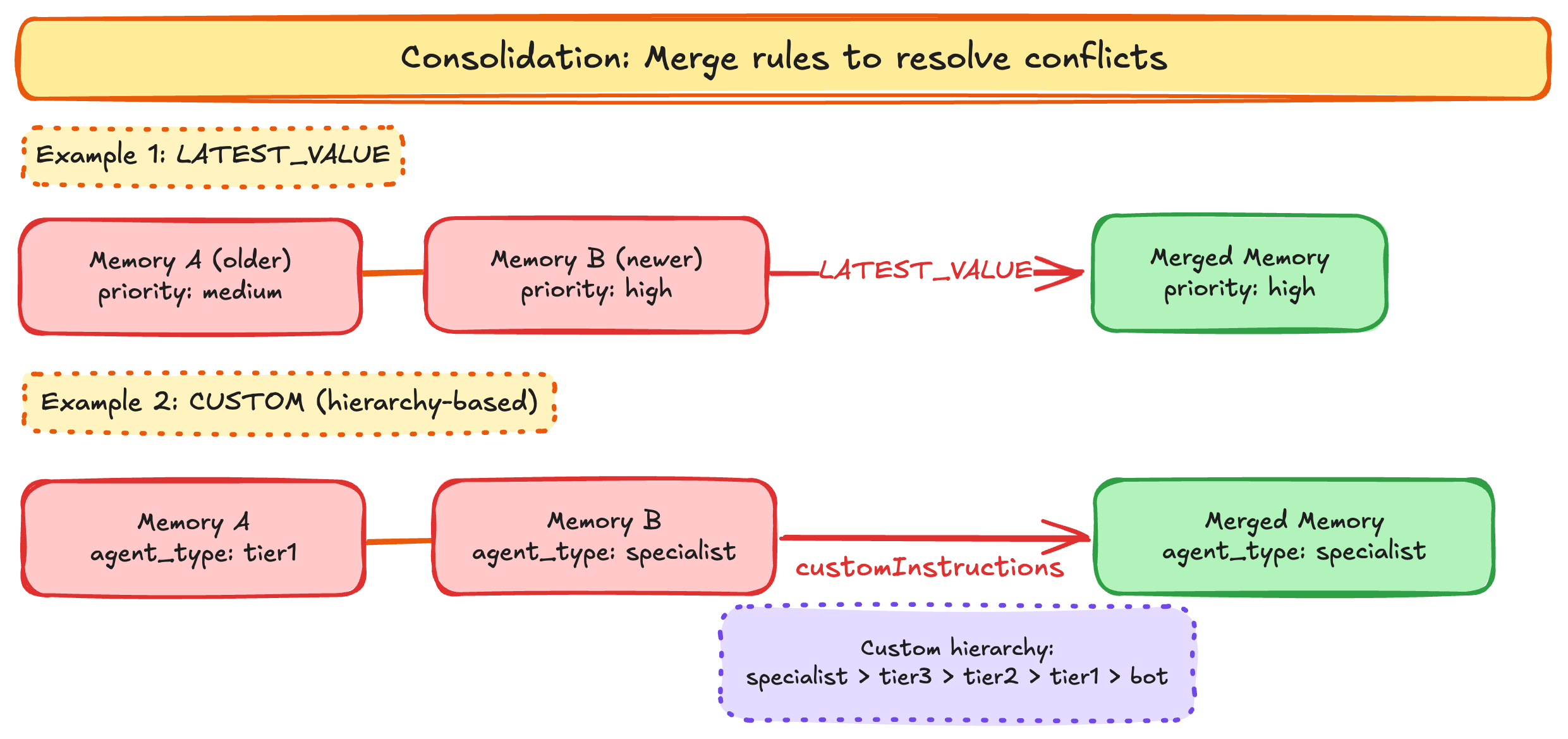
When multiple events in a session carry different values for the same key, the LLM resolves conflicts using the llmExtractionInstruction on that schema entry. For example, if a later ticket event escalates priority from “medium” to “high”, the LATEST_VALUE instruction keeps the “high” priority value (figure 3). A custom hierarchy, like the one in the agent_type field, retains the most specialized agent in the handling chain (figure 3). Note that only metadata keys defined in the strategy’s memoryRecordSchema are populated on resulting memory records. Event metadata keys not in the schema are ignored during extraction.
Deterministic keys follow a different ingestion path. The value you supply on the event is the value that lands on the resulting record. There’s no LLM inference and no conflict resolution, because AgentCore Memory groups events by their deterministic key values before extraction. Events tagged department: "engineering" and events tagged department: "finance" are processed in independent batches, and consolidation operates within these groups. As a result, a record carrying compliance_level: "hipaa" does not merge with one labeled compliance_level: "standard". That’s what makes deterministic extraction well-suited for compliance isolation and routing keys.
If an event arrives without a deterministic key set, the key is omitted from the grouping for that event and absent on the resulting record. The direct-write paths (BatchCreateMemoryRecords and BatchUpdateMemoryRecords) bypass extraction entirely, so the STRICTLY_CONSISTENT extraction type has no effect on them. Supply metadata directly as you already do for those APIs.
Event metadata is not strictly required for schema keys to produce values. When a schema key has no matching metadata on the originating events, the LLM derives the value entirely from conversation content using the key’s definition and llmExtractionInstruction. Consider a schema with three keys; none of which are supplied on events:
The extracted memory record is populated with all three fields inferred from content:
Validation rules still apply: the LLM’s output is constrained to your declared allowedValues regardless of whether the value came from event metadata or content inference. This implicit extraction is useful for dimensions that only exist in the conversation itself, such as topic classification, sentiment, or importance, without requiring callers to supply them at event creation time.
For direct memory record creation, such as importing knowledge bases or ingesting pre-processed records from external systems, you supply metadata explicitly:
Metadata behavior on batch-created records depends on whether you provide an optional memoryStrategyId on each record.
When memoryStrategyId is provided, the service filters the input metadata against that strategy’s memoryRecordSchema. Only keys defined in the schema are stored on the record. Other keys are silently dropped, including indexed keys not in the schema and keys not declared anywhere. This gives you schema-enforced consistency, making sure batch-created records have the same metadata shape as records produced by event-driven extraction.
When memoryStrategyId is omitted, the service stores metadata keys in the payload as-is on the record. This includes keys that are indexed, keys that are in a strategy schema, and keys that are neither. However, only indexed keys are filterable. Attempting to filter on a non-indexed key returns a ValidationException. Non-indexed keys are still visible in getMemoryRecord and listMemoryRecords responses, but they cannot be used in filter expressions.
Phase 3: Retrieval
With metadata indexed and populated on your memory records, you can now combine semantic search with metadata filters to scope results. AgentCore Memory uses a pre-filtering architecture: metadata filters are applied before the vector similarity search runs. This reduces the candidate set first, so the K-nearest neighbor (KNN) search operates on a smaller, more relevant subset. Notice the example below where the results are scoped to only high-priority records from the current year before semantic search matches against “billing issues.”
Notice how combining a custom metadata filter with a system-generated timestamp compacts the candidate set along two dimensions, business priority and recency, before similarity search runs. AgentCore Memory provides multiple operators to cover common query patterns.
AgentCore Memory also adds service-generated metadata fields using the x-amz-agentcore-memory-* prefix, which you can query with the same filter operators to support time-range queries without custom datetime keys.
Why temporal filtering delivers the largest accuracy gains
In our experiments, queries with time-bounded constraints showed the largest improvement with metadata filtering. Structured DATETIME filtering with the BEFORE and AFTER operators converts this into a deterministic index lookup, avoiding ambiguity.
For non-search-based retrieval, ListMemoryRecords provides metadata filtering without semantic search. This is useful when you need to enumerate records matching specific metadata criteria rather than finding semantically similar content. For example, you can list high-priority records for a customer, or pull records tagged with a specific department.
The following example lists high-priority records created after a specific date:
Enterprise use cases
The following examples show how metadata filtering addresses common enterprise retrieval challenges across industries.
Multi-tenant SaaS applications
If you run a SaaS company with AI assistants for multiple enterprise customers, namespaces already provide primary tenant isolation, where each tenant’s memories live in a dedicated namespace like /tenants/{actorId}/. Metadata adds fine-grained filtering within those boundaries to add business dimensions. By indexing metadata keys like customer_segment, department, or subscription_tier, you map retrieval directly to your business hierarchy without maintaining separate memory stores per organizational dimension.
Hierarchical organizational filtering: Within a tenant’s namespace, metadata enables drill-down retrieval scoped to specific departments, teams, or projects. For example, you can retrieve memories only with department: "engineering" and team: "platform" when a platform engineer asks about authentication service issues. This maps directly to enterprise org charts without requiring separate namespaces per organizational unit.
Subscription-tier-aware retrieval: SaaS models can use metadata to differentiate memory behavior by customer tier. An enterprise-tier tenant might get full history retrieval, while a starter-tier tenant gets retrieval scoped to recent memories only (using AFTER datetime filters on x-amz-agentcore-memory-createdAt). This supports feature gating at the memory layer without separate infrastructure per tier.
Healthcare and compliance-sensitive domains
If your healthcare AI agent manages patient interactions across multiple departments, namespaces like patients/patient-123 already isolate each patient’s memories. But within a single patient’s namespace, a broad search for “medication history” returns results from every department: cardiology, endocrinology, and primary care. By indexing metadata keys like department, record_type, severity, and symptoms, your agent can narrow retrieval along multiple clinical dimensions within a patient’s namespace.
The CONTAINS operator on the symptoms STRINGLIST checks whether the list includes the specified value, which scopes retrieval to specific clinical indicators.
For compliance, metadata filtering helps align with regulatory requirements.
- HIPAA: department-level filtering makes sure a cardiologist’s query only retrieves cardiology-relevant records, reducing the risk of surfacing unrelated clinical data.
- GDPR: metadata filters on
x-amz-agentcore-memory-createdAthelp identify records outside retention windows. You handle deletion throughDeleteMemoryRecordor namespace-scoped deletion. - SOC 2: system-generated timestamps provide a verifiable trail that retrieval was correctly scoped. You can also index a
data_classificationkey (with values likePII,confidential, orgeneral) for sensitivity-aware retrieval.
Customer support with priority-based routing
If your support organization handles thousands of tickets, you need agents that prioritize context based on urgency and escalation status. Metadata supports retrieval patterns like “find high-priority billing memories from the last 30 days” by combining custom metadata filters with system timestamp filters. During a live session, your agent pulls the most relevant high-priority context without wading through resolved low-priority issues. As tickets escalate from low to critical, merge rules keep the metadata on consolidated memories aligned with the latest escalation state rather than the initial classification.
Financial services and temporal precision
Financial data is inherently time-sensitive. A query about “Q3 portfolio discussions” must return Q3-specific records, not records from other quarters. A wealth management agent can combine DATETIME filtering with custom metadata to scope retrieval precisely, which helps you avoid noise from other asset classes and time periods:
Multi-agent systems and memory coordination
As agentic systems mature, and become more prominent, metadata becomes critical for how multiple agents share and coordinate through a common memory layer.
- Agent provenance: In multi-agent workflows, knowing which agent created a memory is essential for trust, debugging, and routing. By indexing keys like
source_agent,agent_role, andworkflow_step, the supervisor agent can filter for memories stored by a specific agent. For example, you can filtersource_agent: "billing_agent"within the customer’s namespace to answer “What did the billing agent conclude in the last session?” - Agent-scoped memory visibility: In a multi-agent pipeline (triage bot to tier-1 agent to specialist), you can use metadata to control which memories each agent retrieves. The triage bot writes memories with
workflow_step: "triage". A specialist handling an escalation filters byworkflow_step: "triage"to understand the initial classification, or byagent_role: "tier1"to review what was already attempted, avoiding duplicate work. The customllmExtractionInstructionforagent_rolewould have consolidated memories to reflect the highest-expertise handling, not just the most recent touch. - Metadata-gated retrieval in retrieval augmented generation (RAG) pipelines: A retrieval agent filters by
source_type: "knowledge_base"for factual grounding, a personalization agent filters byinteraction_type: "preference"for user-specific context, and a safety agent filters bycontent_flag: "reviewed"for vetted content. All three query the same namespace but receive completely different result sets without managing multiple memory stores.
Metadata schema evolution
Your production memory systems aren’t static, and metadata schemas need to evolve alongside the applications they serve. AgentCore Memory supports schema evolution through an additive-only update model. You can add new indexed metadata keys to an existing memory resource as needed:
New keys become immediately available for incoming events and memory records. Existing records don’t retroactively receive the new field, but as older memories undergo consolidation with newer ones, they naturally acquire the new metadata. You can’t remove a previously indexed key, which helps prevent accidental loss of filtering capability on existing data. You can freely add, remove, or modify non-indexed keys in strategy-level metadata schemas as your extraction needs evolve.
Best practices
Start with the filtering dimensions your agents need. Avoid indexing every conceivable metadata field upfront. Each indexed field consumes one of your indexed-key slots and adds cost on both paths: more work per-write during ingestion and query compaction on reads. Begin with three to five keys that directly impact retrieval quality, and add more as concrete needs arise.
Write clear, specific definitions. The definition field and llmExtractionInstruction together are the primary instruction the LLM receives for metadata extraction. Instead of “The priority of the ticket,” write “Issue priority level based on customer impact. Use ‘critical’ for service outages affecting production, ‘high’ for degraded performance, ‘medium’ for feature requests, ‘low’ for documentation or cosmetic issues.”
Choose merge rules that match domain semantics. LATEST_VALUE is a safe default for most fields, but not always correct. For agent_type in a support escalation workflow, the most senior agent type should be retained, not the most recent one. Custom merge instructions would express this domain logic.
Constrain LLM output with validation rules. Define allowedValues in the validation field to enforce a controlled vocabulary. Without validation, the LLM might produce “High”, “high”, “HIGH”, or “critical” for the same concept, breaking downstream filter matching.
Design for the event-driven pathway for keys whose values are known at event time and stay constant across the events in a session, such as department or tenant_tier. Attach metadata to events and let AgentCore Memory propagate it through extraction for automatic conflict resolution and consolidation handling. Reserve the direct batch API pathway for bulk imports and pre-processed content where you already know the correct metadata values.
Plan metadata schemas at the strategy level. Each memory strategy can have its own metadata schema, allowing different strategies to extract and handle the same keys differently. A semantic strategy might use custom extraction instructions to classify priority from conversation context, while a summary strategy might use a different definition tuned for summarization-specific metadata. This flexibility supports optimized metadata handling per strategy without compromising the shared indexed key infrastructure.
Be intentional with memoryStrategyId on batch-created records. When you include memoryStrategyId on a batch-create request, the service filters input metadata to only the keys in that strategy’s schema, and other keys are silently dropped. This is useful for enforcing consistency with extraction-produced records. When you omit it, metadata in the payload is stored as-is. Choose based on your use case: schema-enforced consistency for records that should look like extracted ones, or full control for bulk imports where you manage metadata externally.
Use non-indexed schema keys for context enrichment. Not every metadata key needs to be filterable. Schema keys that aren’t declared as indexed keys are still populated on extracted records and visible in get and list responses, but they can’t be used in filter expressions. This is useful for metadata that enriches the record for downstream consumption (for example, sentiment, summary_notes, or source_url) without consuming your indexed key budget. Reserve indexed keys for dimensions you actively filter on.
Use deterministic extraction for values you already know. If a key represents a fixed organizational attribute that the agent has at event creation time, like department, tenant tier, or compliance scope, configure it as STRICTLY_CONSISTENT and supply it on every event. This guarantees exact values on the resulting records and removes normalization drift (“eng” compared to “Engineering”) that LLM extraction can introduce. Reserve llmExtractionConfig for dimensions that must be inferred from conversation content, like sentiment or topic.
Avoid these anti-patterns:
- Don’t index high-cardinality free-text fields like descriptions or full names, these bloat the index without useful filter boundaries.
- Don’t use metadata for values that change on every interaction; metadata is most effective for stable or slowly-changing attributes.
- Don’t replicate namespace isolation through metadata alone. A
tenant_idmetadata field without namespace isolation is a security-through-convention model that breaks on any missed filter.
Conclusion
Metadata filtering in AgentCore Memory addresses a fundamental retrieval challenge. Namespaces already isolate memories by primary entities like users, tenants, or projects. With structured metadata filtering layered on top of namespace scoping, you can narrow your agent’s retrieval to precise contextual boundaries before similarity matching runs, delivering measurably better accuracy and a practical foundation for compliance, priority-based context management, and fine-grained organizational filtering. LLM-driven extraction avoids the manual tagging burden, while configurable extraction instructions handle metadata propagation and conflict resolution at scale.
To get started, identify three to five filtering dimensions that most directly impact retrieval quality for your use case. Begin with a proof of concept (PoC) using a dummy memory resource to test the relevant strategies, then expand the schema as concrete needs arise. The following resources provide hands-on guidance:
- Amazon Bedrock AgentCore documentation.
- AgentCore Memory code samples.
- Blog on Amazon Bedrock AgentCore Memory: Building context-aware agents.
About the authors
In this post, you will learn how metadata works across configuration, ingestion, and retrieval, explore enterprise use cases including multi-agent and multi-tenant architectures, and discover best practices for implementation. Read More