Large language models (LLMs) have transformed how we process and generate information, but they still struggle with effectively integrating knowledge across multiple sources. Standard Retrieval Augmented Generation (RAG) methods, although helpful, often fall short when tackling multi-hop reasoning tasks that require connecting information from separate documents. To address these limitations, we explore HippoRAG, a novel RAG framework inspired by the hippocampal memory system in human brains.
In this post, we demonstrate how to implement HippoRAG using a comprehensive AWS stack. We use Amazon Bedrock for LLM capabilities, Amazon Neptune for graph database functionality, Amazon Neptune Analytics for advanced graph algorithms including Personalized PageRank, and Amazon Titan Embeddings for vector representations. This implementation showcases how to build and deploy HippoRAG within AWS infrastructure for enterprise-scale applications.
Neurobiological inspiration and background
HippoRAG draws inspiration from the hippocampal indexing theory of human long-term memory. In human brains, the neocortex processes perceptual inputs, whereas the hippocampus creates an index of associations between memories. This dual-component system allows humans to efficiently integrate information across different experiences.
Standard RAG approaches treat each document independently, struggling with questions that require connecting information across multiple sources. HippoRAG addresses this by:
- Building a knowledge graph (KG) to represent relationships between entities.
- Using the Personalized PageRank (PPR) algorithm for efficient graph traversal and relevance ranking.
- Enabling single-step multi-hop retrieval instead of requiring multiple iterations.
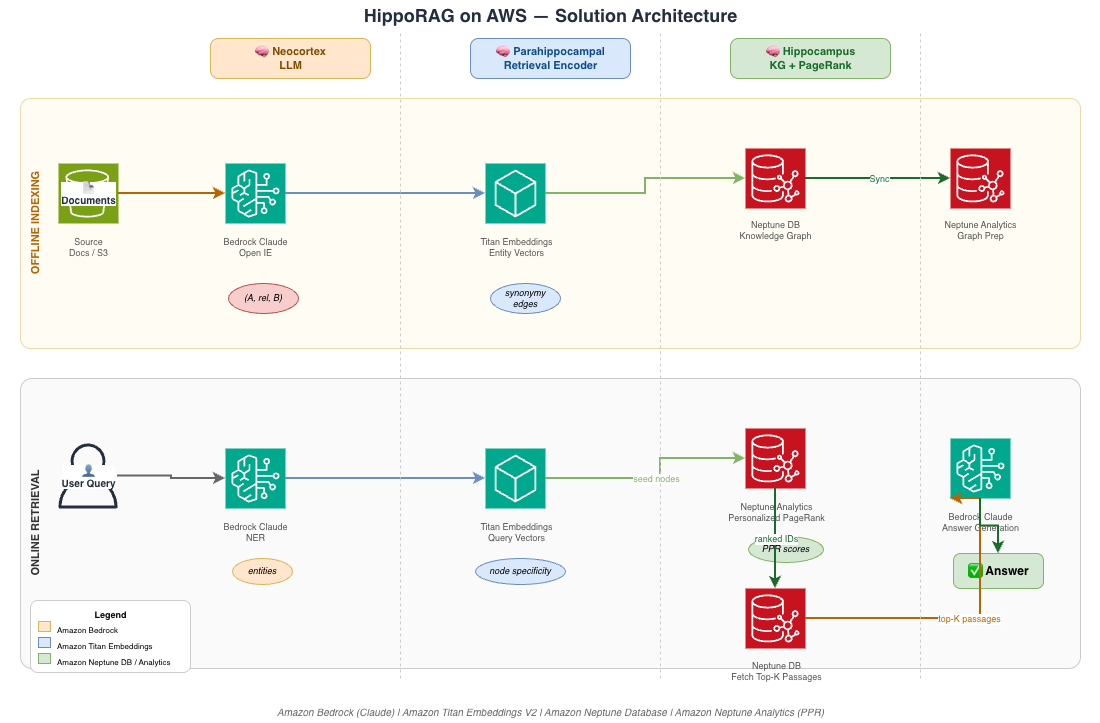
Solution architecture
Our AWS implementation of HippoRAG involves four main components:
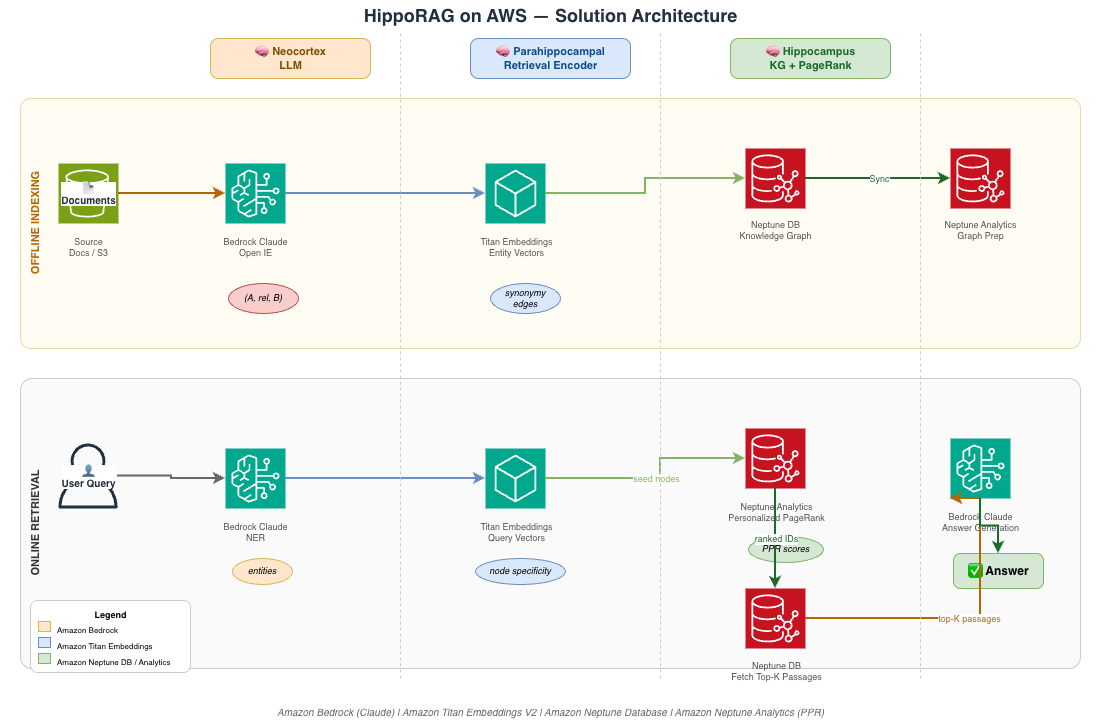
- Amazon Bedrock – Provides LLM capabilities for extracting knowledge graph triples, answering questions, and identifying named entities.
- Amazon Neptune Database – Stores the knowledge graph structure and enables basic graph operations.
- Amazon Neptune Analytics – Executes advanced graph algorithms, particularly Personalized PageRank for relevance ranking.
- Amazon Titan Embeddings – Creates vector representations of text for similarity matching.
This architecture allows us to use the full power of personalized PageRank while maintaining the scalability and reliability of AWS managed services.
Prerequisites
For this implementation, you’ll need:
- An AWS account with access to Amazon Bedrock and Neptune services.
- Amazon Neptune cluster configured and accessible.
- Amazon Neptune Analytics graph created from your Neptune Database.
- AWS Command Line Interface (AWS CLI) and Python 3.8+ installed.
- Appropriate IAM permissions for: Amazon Bedrock | Amazon Neptune | Amazon Neptune Analytics | Amazon Simple Storage Service (Amazon S3).
Data processing pipeline: From HotpotQA JSON to Neptune
A necessary first step in implementing HippoRAG is converting raw data into a knowledge graph structure suitable for Neptune. In this section, we walk through how we process HotpotQA data from JSON format. We extract knowledge-graph triples using Amazon Bedrock, generate Neptune bulk-load CSV files, upload them to Amazon S3, and load them into our Neptune cluster. Each of the following subsections corresponds to a stage of that pipeline.
Setting up the data importer
The HotpotQANeptuneImporter class orchestrates every stage of the pipeline. It handles reading the JSON source file, generating CSV outputs, uploading those files to Amazon S3, and triggering the Neptune bulk loader. Let’s look at how we initialize this class with the configuration values for our AWS environment:
Knowledge graph triple extraction
A key part of the pipeline is using Amazon Bedrock’s LLM capabilities to extract structured knowledge from raw text. For each passage, the system generates subject-relation-object triples that become edges in the knowledge graph. Here’s how we implement that extraction:
Converting JSON data to CSV format
With triples in hand, we need to serialize the graph into the CSV format that Neptune’s bulk loader expects. This processing method converts the HotpotQA JSON records into four CSV files: phrase_nodes.csv, passage_nodes.csv, relation_edges.csv, and context_edges.csv. Together, these files capture the full knowledge graph structure. Here’s how we implement that conversion:
Processing individual examples
Each HotpotQA example is processed to create nodes and edges in the knowledge graph:
Loading data to Neptune
After processing the data into CSV files, the system uploads them to S3 and imports them into Neptune:
Running the full pipeline
You can run the full data processing pipeline with the following steps:
Implementation
This section walks through the key components of the HippoRAG implementation, from initial configuration to knowledge graph construction and retrieval.
Configuration
First, let’s set up the basic configuration for our HippoRAG implementation:
Neptune Analytics integration
A key innovation in our implementation is the integration with Amazon Neptune Analytics for personalized PageRank. We create a dedicated client to handle advanced graph analytics:
Knowledge graph construction
HippoRAG builds a knowledge graph from documents using LLM capabilities of Amazon Bedrock. This process extracts entities and relationships from text:
The indexing process involves:
- Extracting named entities from passages using Claude LLM.
- Creating knowledge graph triples using open information extraction.
- Computing embeddings for entities using Amazon Titan Embeddings.
- Storing the graph structure in Amazon Neptune Database.
- Adding synonymy edges between similar entities.
- Preparing the graph for Neptune Analytics processing.
Personalized PageRank retrieval
The core advantage of HippoRAG is its ability to perform sophisticated multi-hop retrieval using personalized PageRank. Our implementation uses Neptune Analytics for this:
Setting up Neptune Analytics
Before running the implementation, you need to create a Neptune Analytics graph from your Neptune Database:
Demo and results
Let’s walk through a demonstration of our AWS native HippoRAG implementation with personalized pagerank:
From our test results, we can see that HippoRAG with personalized PageRank correctly retrieves and ranks documents:
Question: Who painted the Mona Lisa?
Answer: Leonardo da Vinci
Top documents (PageRank ranked):
Doc 1 (Score: 0.8234): Leonardo da Vinci painted the Mona Lisa between 1503 and 1519...
Doc 2 (Score: 0.6891): The Mona Lisa is housed in the Louvre Museum in Paris...
Doc 3 (Score: 0.5432): Da Vinci was an Italian Renaissance artist known for...
Question: What is the connection between Leonardo da Vinci and France?
Answer: Leonardo da Vinci died in France in 1519, where he spent his final years under the patronage of King Francis I.
Top documents (PageRank ranked):
Doc 1 (Score: 0.9156): Leonardo da Vinci died at Château du Clos Lucé in France in 1519...
Doc 2 (Score: 0.7832): King Francis I of France invited Leonardo to work at his court...
Doc 3 (Score: 0.6234): The artist spent his final three years in Amboise, France...The last question demonstrates HippoRAG’s ability to connect information across multiple documents. It uses personalized PageRank to rank the most relevant passages based on their graph-theoretic importance relative to the query entities.
Path-finding multi-hop retrieval
One of HippoRAG’s most impressive capabilities is solving what the researchers call “path-finding” multi-hop questions. Unlike “path-following” questions with a clear directed path between entities, path-finding questions require exploring multiple potential paths to find connections.
Consider this example: Question: Which Stanford professor works on the neuroscience of Alzheimer’s?
For this question, HippoRAG with personalized PageRank can directly navigate the knowledge graph. It uses the PageRank algorithm to identify and rank the most relevant paths that connect Stanford, neuroscience, and Alzheimer’s research.
The personalized PageRank algorithm starts from seed nodes related to “Stanford,” “neuroscience,” and “Alzheimer’s.” It then propagates relevance scores through the graph to identify entities and passages that are most strongly connected to the query concepts.
This capability is particularly valuable for complex enterprise use cases like scientific literature review, legal case analysis, or medical diagnosis.
Benefits and performance
The HippoRAG approach implemented with this comprehensive AWS stack offers several key benefits:
- High performance: HippoRAG is a well-performing variant of GraphRAG that excels at complex multi-hop reasoning tasks.
- Single-step efficiency: Personalized PageRank enables direct multi-hop retrieval that is different from iterative methods.
- Advanced graph analytics: Neptune Analytics provides personalized PageRank computation with high performance and scalability.
- AWS integration: Fully uses managed services like Amazon Bedrock, Neptune, and Neptune Analytics for reliability and ease of management.
- Continuous learning: Updates with new information without requiring model retraining.
- Enterprise ready: Secure, scalable, and compatible with existing AWS infrastructures.
The high performance comes from the fundamental approach of using graph-based retrieval with personalized PageRank. The AWS native stack provides significant operational advantages in terms of scalability, security, and maintenance.
Clean up
- When you’re done, clean up your resources to stop incurring costs. You can do so using the AWS Management Console. For instructions, refer to the Amazon Neptune, Amazon Neptune Analytics, Amazon Bedrock, and Amazon S3 documentation. You can also delete any IAM roles and policies created as part of this walkthrough.
Conclusion
HippoRAG with personalized PageRank provides a viable alternative to standard GraphRAG for multi-document question answering. By implementing it with Amazon Bedrock, Neptune Database, Neptune Analytics, and Amazon Titan Embeddings, we’ve created a powerful, neurobiologically inspired solution. This solution can tackle complex multi-hop reasoning tasks with sophisticated relevance ranking.
This approach demonstrates how AWS services can be combined to create sophisticated artificial intelligence (AI) solutions that go beyond standard RAG implementations. The integration of graph-based retrieval with personalized PageRank and state-of-the-art LLMs opens new possibilities for enterprise applications requiring deep knowledge integration across multiple sources.
We look forward to seeing how you apply this technology to your own use cases!
References
- HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models (original research paper).
- Amazon Bedrock documentation.
- Amazon Neptune documentation.
- Amazon Neptune Analytics documentation.
- Amazon Titan Embeddings documentation.
About the authors
In this post, we demonstrate how to implement HippoRAG using a comprehensive AWS stack. We use Amazon Bedrock for LLM capabilities, Amazon Neptune for graph database functionality, Amazon Neptune Analytics for advanced graph algorithms including Personalized PageRank, and Amazon Titan Embeddings for vector representations. This implementation showcases how to build and deploy HippoRAG within AWS infrastructure for enterprise-scale applications. Read More