Speaker diarization, an essential process in audio analysis, segments an audio file based on speaker identity. This post delves into integrating Hugging Face’s PyAnnote for speaker diarization with Amazon SageMaker asynchronous endpoints.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. You can use this solution for applications dealing with multi-speaker (over 100) audio recordings.
Solution overview
Amazon Transcribe is the go-to service for speaker diarization in AWS. However, for non-supported languages, you can use other models (in our case, PyAnnote) that will be deployed in SageMaker for inference. For short audio files where the inference takes up to 60 seconds, you can use real-time inference. For longer than 60 seconds, asynchronous inference should be used. The added benefit of asynchronous inference is the cost savings by auto scaling the instance count to zero when there are no requests to process.
Hugging Face is a popular open source hub for machine learning (ML) models. AWS and Hugging Face have a partnership that allows a seamless integration through SageMaker with a set of AWS Deep Learning Containers (DLCs) for training and inference in PyTorch or TensorFlow, and Hugging Face estimators and predictors for the SageMaker Python SDK. SageMaker features and capabilities help developers and data scientists get started with natural language processing (NLP) on AWS with ease.
The integration for this solution involves using Hugging Face’s pre-trained speaker diarization model using the PyAnnote library. PyAnnote is an open source toolkit written in Python for speaker diarization. This model, trained on the sample audio dataset, enables effective speaker partitioning in audio files. The model is deployed on SageMaker as an asynchronous endpoint setup, providing efficient and scalable processing of diarization tasks.
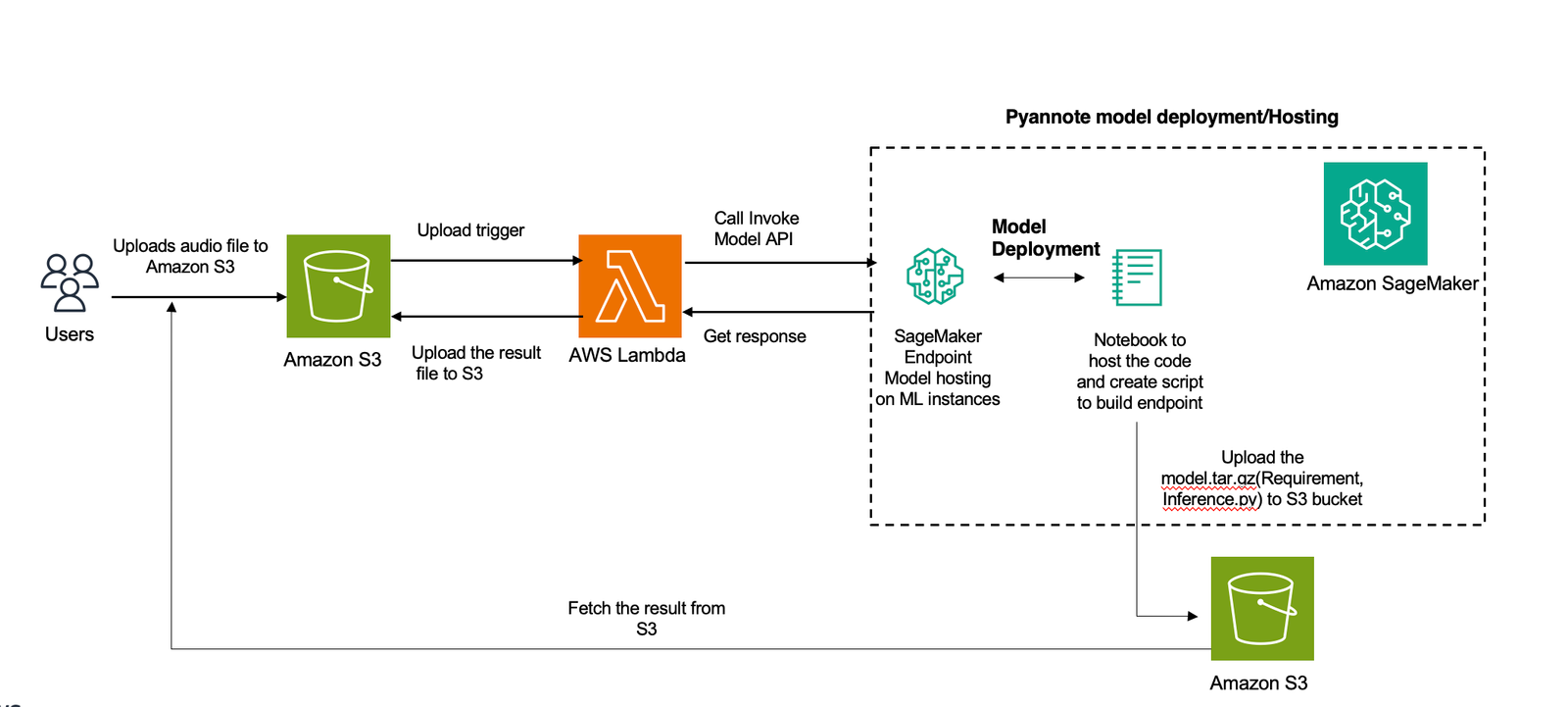
The following diagram illustrates the solution architecture.
For this post, we use the following audio file.
Stereo or multi-channel audio files are automatically downmixed to mono by averaging the channels. Audio files sampled at a different rate are resampled to 16kHz automatically upon loading.
Prerequisites
Complete the following prerequisites:
Create a SageMaker domain.
Make sure your AWS Identity and Access Management (IAM) user has the necessary access permissions for creating a SageMaker role.
Make sure the AWS account has a service quota for hosting a SageMaker endpoint for an ml.g5.2xlarge instance.
Create a model function for accessing PyAnnote speaker diarization from Hugging Face
You can use the Hugging Face Hub to access the desired pre-trained PyAnnote speaker diarization model. You use the same script for downloading the model file when creating the SageMaker endpoint.
See the following code:
Prepare essential files like inference.py, which contains the inference code:
Prepare a requirements.txt file, which contains the required Python libraries necessary to run the inference:
Lastly, compress the inference.py and requirements.txt files and save it as model.tar.gz:
Configure a SageMaker model
Define a SageMaker model resource by specifying the image URI, model data location in Amazon Simple Storage Service (S3), and SageMaker role:
Upload the model to Amazon S3
Upload the zipped PyAnnote Hugging Face model file to an S3 bucket:
Create a SageMaker asynchronous endpoint
Configure an asynchronous endpoint for deploying the model on SageMaker using the provided asynchronous inference configuration:
Test the endpoint
Evaluate the endpoint functionality by sending an audio file for diarization and retrieving the JSON output stored in the specified S3 output path:
To deploy this solution at scale, we suggest using AWS Lambda, Amazon Simple Notification Service (Amazon SNS), or Amazon Simple Queue Service (Amazon SQS). These services are designed for scalability, event-driven architectures, and efficient resource utilization. They can help decouple the asynchronous inference process from the result processing, allowing you to scale each component independently and handle bursts of inference requests more effectively.
Results
Model output is stored at s3://sagemaker-xxxx /async_inference/output/. The output shows that the audio recording has been segmented into three columns:
Start (start time in seconds)
End (end time in seconds)
Speaker (speaker label)
The following code shows an example of our results:
Clean up
You can set a scaling policy to zero by setting MinCapacity to 0; asynchronous inference lets you auto scale to zero with no requests. You don’t need to delete the endpoint, it scales from zero when needed again, reducing costs when not in use. See the following code:
Speaker diarization, an essential process in audio analysis, segments an audio file based on speaker identity. This post delves into integrating Hugging Face’s PyAnnote for speaker diarization with Amazon SageMaker asynchronous endpoints. We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. Read More