As companies of all sizes continue to build generative AI applications, the need for robust governance and control mechanisms becomes crucial. With the growing complexity of generative AI models, organizations face challenges in maintaining compliance, mitigating risks, and upholding ethical standards. This is where the concept of guardrails comes into play, providing a comprehensive framework for implementing governance and control measures with safeguards customized to your application requirements and responsible AI policies.
Amazon Bedrock Guardrails helps implement safeguards for generative AI applications based on specific use cases and responsible AI policies. Amazon Bedrock Guardrails assists in controlling the interaction between users and foundation models (FMs) by detecting and filtering out undesirable and potentially harmful content, while maintaining safety and privacy. Organizations can define denied topics, making sure that FMs refrain from providing information or advice on undesirable subjects; configure content filters to set thresholds for blocking harmful content across categories such as hate, insults, sexual, violence, and misconduct; redact sensitive and personally identifiable information (PII) to protect privacy; and block inappropriate content with a custom word filter. You can create multiple guardrails with different configurations, each tailored to specific use cases, and continuously monitor and analyze user inputs and FM responses that might violate customer-defined policies. By proactively implementing guardrails, companies can future-proof their generative AI applications while maintaining a steadfast commitment to ethical and responsible AI practices.
In this post, we explore a solution that automates building guardrails using a test-driven development approach.
Iterative development
Although implementing Amazon Bedrock Guardrails is a crucial step in practicing responsible AI, it’s important to recognize that these safeguards aren’t static. As models evolve and new use cases emerge, organizations must be proactive in refining and adapting their guardrails to maintain effectiveness and alignment with their responsible AI policies.
To address this challenge, we recommend builders adopt a test-driven development (TDD) approach when building and maintaining their guardrails. TDD is a software development methodology that emphasizes writing tests before implementing actual code. By applying this methodology to guardrails, organizations can proactively identify edge cases, potential vulnerabilities, and areas for improvement, making sure that their guardrails remain robust and fit for purpose. TDD for guardrails offers several benefits. It promotes a structured and systematic approach to refining and validating guardrails, reducing the risk of unintended consequences or gaps in coverage. Additionally, TDD facilitates collaboration and knowledge sharing among teams, because tests serve as living documentation and a shared understanding of the expected behavior and constraints.
In this post, we present a solution that takes a TDD approach to guardrail development, allowing you to improve your guardrails over time.
Solution overview
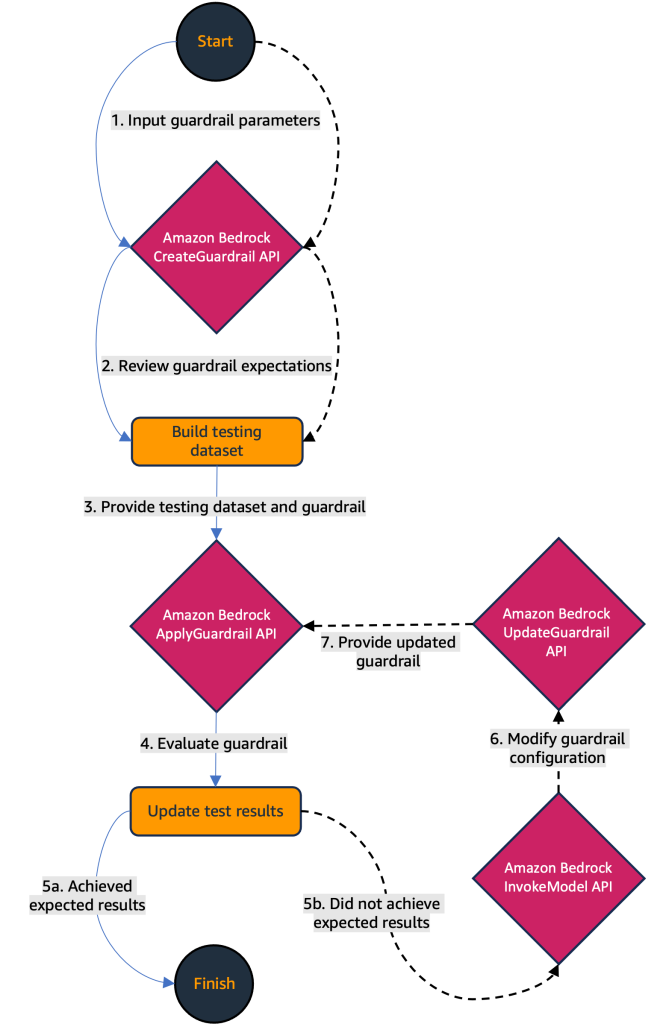
In this solution, you use a TDD approach to improve your guardrails. You first create a guardrail, then build a testing dataset, and finally evaluate the guardrail using the testing dataset. Using the test results from your evaluation of the guardrail, you can go back and update it and reevaluate. This allows you to maintain the TDD approach and improve your guardrail over multiple iterations. The solution also includes an optional step where you invoke an FM to generate and implement changes to your guardrail based on the test results; we recommend using that step to understand the different ways to update the guardrail because it doesn’t guarantee all test cases will pass.
This workflow is shown in the following diagram.
This diagram presents the main workflow (Steps 1–4) and the optional automated workflow (Steps 5–7).
Prerequisites
Before you start, make sure you have the following prerequisites in place:
Create an AWS account, or sign in to your existing account.
Make sure that you have the correct AWS Identity and Access Management (IAM) permissions to use Amazon Bedrock.
Have access to the large language model (LLM) that will be used. This solution uses Anthropic’s Claude 3 Sonnet and Claude 3 Haiku models.
Install Python 3.8 or greater in your environment.
Install pip.
Configure your AWS credentials.
Clone the repo
To get started, clone the repository by running the following command, and then switch to the working directory:
Build your guardrail
To build the guardrail, you can use the CreateGuardrail API. There are multiple components to a guardrail for Amazon Bedrock. This API allows you to configure the following policies programmatically:
Content filters – You can configure thresholds to block input prompts or model responses containing harmful content such as hate, insults, sexual, violence, misconduct (including criminal activity), and prompt attacks (prompt injection and jailbreaks). For example, an ecommerce site can design its online assistant to not use inappropriate language, such as hate speech or insults.
Denied topics – You can define a set of topics to deny within your generative AI application. For example, a banking assistant application can be designed to deny topics related to illegal investment advice.
Word filters – You can configure a set of custom words or phrases that you want to detect and block in the interaction between your users and generative AI applications. For example, you can detect and block profanity as well as specific custom words such as competitor names, or other offensive words.
Sensitive information filters – You can detect sensitive content such as PII or custom regular expressions (regex) entities in user inputs and FM responses. Based on the use case, you can reject inputs that contain sensitive information or redact them in FM responses. For example, you can redact users’ PII while generating summaries from customer and agent conversation transcripts.
Contextual grounding check – You can detect and filter hallucinations in model responses if they aren’t grounded (factually inaccurate or add new information) in the source information or are irrelevant to the user’s query. For example, you can block or flag responses in Retrieval Augmented Generation (RAG) applications if the model’s responses deviate from the information in the retrieved passages or don’t answer the user’s questions.
To test this solution, you create a guardrail for a math tutoring business, which stops the model from providing responses for non-math tutoring, in-person tutoring, or tutoring outside grades 6–12 requests. See the following code:
Amazon Bedrock Guardrails helps implement safeguards for generative AI applications based on specific use cases and responsible AI policies. Amazon Bedrock Guardrails assists in controlling the interaction between users and foundation models (FMs) by detecting and filtering out undesirable and potentially harmful content, while maintaining safety and privacy. In this post, we explore a solution that automates building guardrails using a test-driven development approach. Read More