Organizations and individuals running multiple custom AI models, especially recent Mixture of Experts (MoE) model families, can face the challenge of paying for idle GPU capacity when the individual models don’t receive enough traffic to saturate a dedicated compute endpoint. To solve this problem, we have partnered with the vLLM community and developed an efficient solution for Multi-Low-Rank Adaptation (Multi-LoRA) serving of popular open-source MoE models like GPT-OSS or Qwen. Multi-LoRA is a popular approach to fine-tune models. Instead of retraining entire model weights, multi-LoRA keeps the original weights frozen and injects small, trainable adapters into the model’s layers. With multi-LoRA, at inference time, multiple custom models share the same GPU, with only the adapters swapped in and out per request. For example, five customers each utilizing only 10% of a dedicated GPU can be served from a single GPU with multi-LoRA, turning five underutilized GPUs into one efficiently shared GPU.
In this post, we explain how we implemented multi-LoRA inference for Mixture of Experts (MoE) models in vLLM, describe the kernel-level optimizations we performed, and show you how you can benefit from this work. We use GPT-OSS 20B as our primary example throughout this post.
You can use these improvements today in your local vLLM deployments with version 0.15.0 or later. Multi-LoRA serving now works for MoE model families including GPT-OSS, Qwen3-MoE, DeepSeek, and Llama MoE. Our optimizations also help improve multi-LoRA hosting for dense models, e.g., Llama3.3 70B or Qwen3 32B. Amazon-specific optimizations deliver additional latency improvements over vLLM 0.15.0, e.g., 19% higher Output Tokens Per Second (OTPS) (i.e., how fast the model generates output) and 8% lower Time To First Token (TTFT) (i.e., how long you have to wait before the model starts to generate output) for GPT-OSS 20B. To benefit from these optimizations, host your LoRA customized models on Amazon SageMaker AI or Amazon Bedrock.
Implementing multi-LoRA inference for MoE models in vLLM
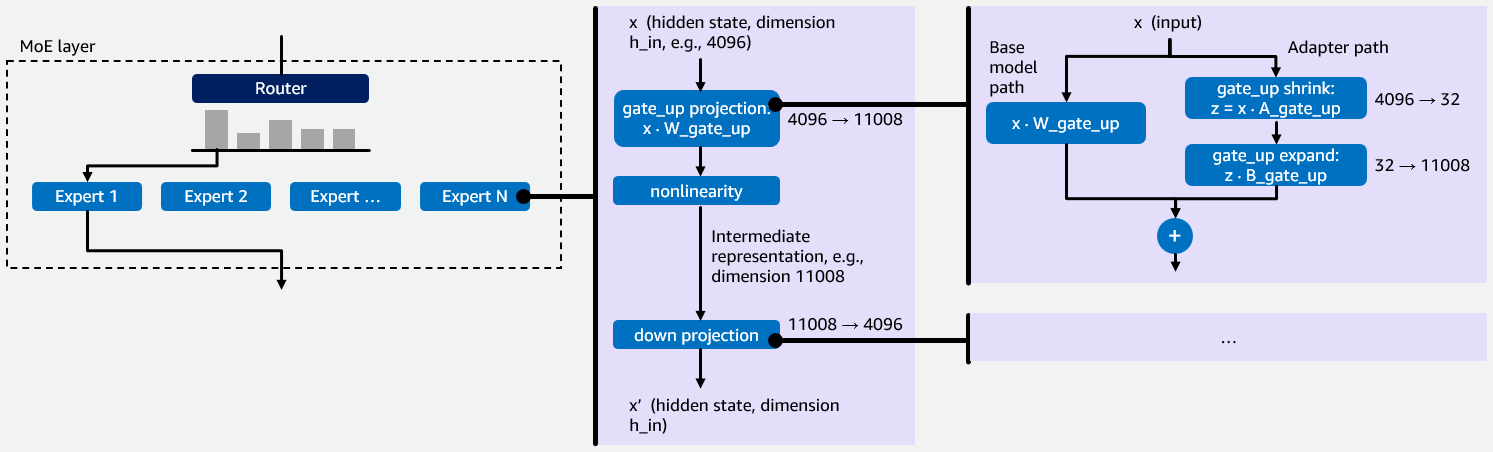
Before we dive into our initial implementation of multi-LoRA inference for MoE models in vLLM, we want to provide some background information on MoE models and LoRA fine-tuning that is important for understanding the rationale behind our optimizations. MoE models contain multiple specialized neural networks called experts. A router directs each input token to the most relevant experts, whose outputs are then aggregated. This sparse architecture processes larger models with fewer computational resources because only a fraction of the model’s total parameters are activated per token, see Figure 1 below for a visualization.
Each expert is a small feed-forward network that processes a token’s hidden state in two stages. First, the gate_up projection expands the compact hidden state (e.g., 4096 dims) into a larger intermediate space (e.g., 11008 dims). This expansion is necessary because features in the compact space are tightly entangled – the larger space gives the network room to pull them apart, transform them, and selectively gate which ones matter. Second, the down projection compresses the result back to the original dimension. This helps keep the output compatible with the rest of the model and acts as a bottleneck, forcing the network to retain only the most useful features. Together, this “expand-then-compress” pattern lets each expert apply rich transformations while maintaining a consistent output size. vLLM uses a fused_moe kernel to execute these projections as Group General Matrix Multiply (Group GEMM) operations — one GEMM per expert assigned to a given token. Multi-LoRA fine-tuning keeps the base model weights W, e.g., W_gate_up for the gate_up projection, frozen and trains two small matrices A and B that together form an adapter. For a projection with base weights W of shape h_in × h_out, LoRA trains A of shape h_in × r and B of shape r × h_out, where r is the LoRA rank (typically 16-64). The fine-tuned output becomes y = xW + xAB. Each LoRA adapter adds two operations to a projection. The shrink operation computes z=xA, reducing the input from h_in dimensions down to r dimensions. The expand operation takes that r-dimensional result and projects it back to h_out dimensions by multiplying z with B. This is illustrated on the right of Figure 1.
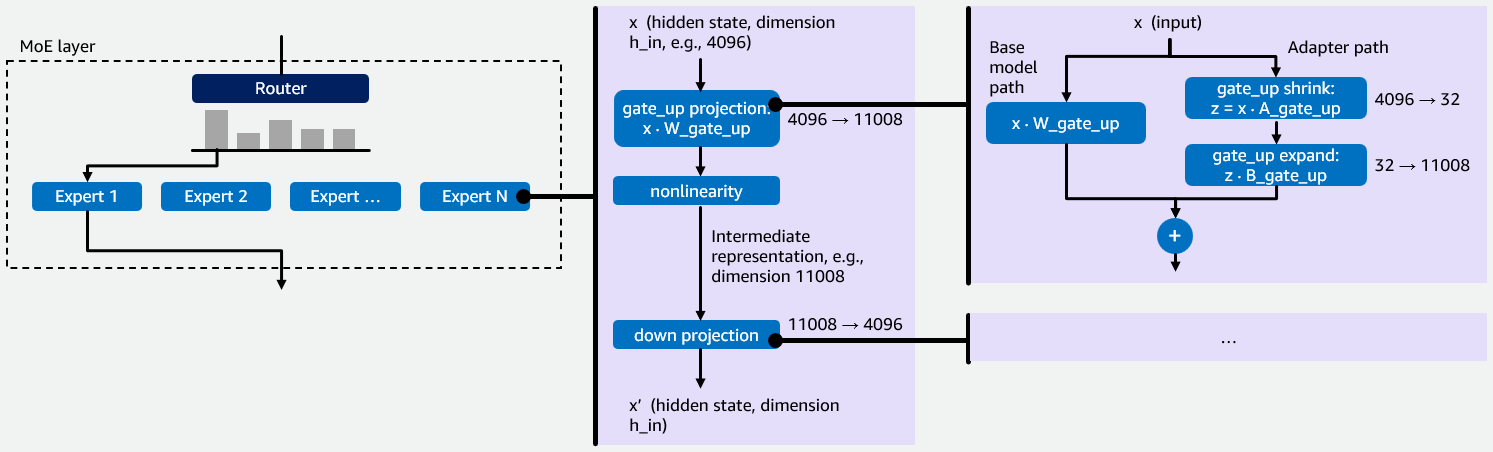
Figure 1: Illustration of how MoE-LoRA models work with an example hidden state dimension 4096, intermediate representation dimension 11008 and LoRA rank r = 32.
Each expert has two weight projections: gate_up and down. When a LoRA adapter is applied, it adds two low-rank operations, i.e., shrink and expand, to each projection. This means every expert requires four LoRA kernel operations in total: shrink and expand for gate_up, and shrink and expand for down. In a multi-LoRA serving setup, where multiple LoRA adapters are served simultaneously for different users or tasks, the system must efficiently manage these four operations per expert, per adapter, per request. This makes it a key performance bottleneck for MoE models. The four operations involve matrices, where one dimension (the LoRA rank r) is 100-300× smaller than the other (e.g., hidden state and intermediate representation dimension). Standard GEMM kernels are designed for roughly square matrices and perform poorly on skinny matrices, which is why the kernel optimizations described later in this post are necessary. Besides having to optimize for skinny matrices, adding multi-LoRA support for MoE models presented two technical challenges. First, vLLM lacked a kernel to perform LoRA on MoE layers because existing dense multi-LoRA kernels do not handle expert routing. Second, MoE LoRA combines two sources of sparsity: expert routing (tokens assigned to different experts) and adapter selection (requests using different LoRA adapters). This compound sparsity requires a specialized kernel design. To address these challenges, we created a fused_moe_lora kernel that integrates LoRA operations into the fused_moe kernel. This new kernel performs LoRA shrink and expand GEMMs for the gate_up and down projections. The fused_moe_lora kernel follows the same logic as the fused_moe kernel and adds an additional dimension to the grid for the corresponding activated LoRA adapters.
With this implementation merged into vLLM, we could run a multi-LoRA serving with GPT-OSS 20B on an H200 GPU, reaching 26 OTPS and 1053 ms TTFT on the Sonnet dataset (a poetry-based benchmark) with input length of 1600, output length of 600 and concurrency of 16. To reproduce these results, check out our PR in the release 0.11.1.rc3 from the vLLM GitHub repository. In the rest of this blog, we will show how we optimized the performance from these baseline enablement numbers.
Improving multi-LoRA inference performance in vLLM
After finalizing our initial implementation, we used NVIDIA Nsight Systems (Nsys) to identify bottlenecks and found the fused_moe_lora kernel to be the highest-latency component. We then used NVIDIA Nsight Compute (NCU) to profile compute and memory throughput for the four kernel operations: gate_up_shrink, gate_up_expand, down_shrink, and down_expand. These findings led us to develop execution optimizations, kernel-level optimizations, and tuned configurations for these four kernels.
Execution optimizations
With our initial implementation, the multi-LoRA TTFT was 10x higher (worse) than the base model TTFT (i.e., the public release version of GPT-OSS 20B). Our profiling revealed that the Triton compiler treated input-length-dependent variables as compile-time constants, causing the fused_moe_lora kernel to be recompiled from scratch for every new context length instead of being reused. This is visible in Figure 2: the cuModuleLoadData calls before each fused_moe_lora kernel execution indicate that the GPU is loading a newly compiled kernel binary rather than reusing a cached one, and the large gaps between kernel start times show the GPU sitting idle during recompilation. This overhead drove the 10× TTFT regression over the base model. We resolved this by adding a do_not_specialize compiler hint for these variables, instructing Triton to compile the kernel once and reuse it across all context lengths.
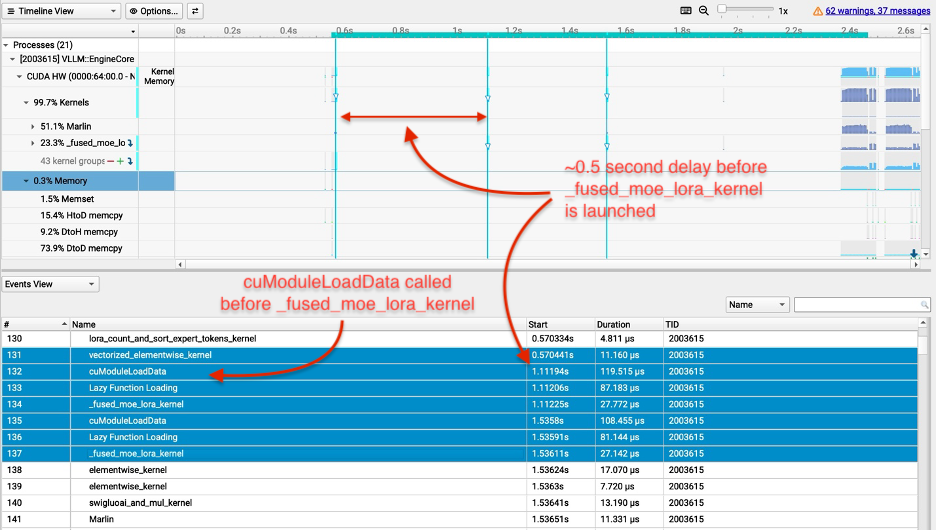
Figure 2: Profiling results for fused_moe_lora kernel before our execution optimizations.
Profiling also revealed that our fused_moe_lora kernel launched with the same high overhead regardless of whether the request used the base model only, attention-only adapters (LoRA adapters with weights only on the attention layers), or full LoRA adapters (adapters with weights on both attention and MoE layers). To help resolve this, we added early exit logic to skip the fused_moe_lora kernel on layers without LoRA adapters, helping prevent unnecessary kernel execution.
The shrink and expand kernels run serially, which created bubbles between executions of two kernels in our early implementation. To overlap the kernel execution, we implemented Programmatic Dependent Launch (PDL). With PDL, a dependent kernel can begin to launch before the primary kernel finishes, which lets the expand kernel pre-fetch weights into shared memory and L2 cache while the shrink kernel runs. When the shrink kernel completes, the expand kernel has already loaded its weights and can immediately begin computation.
We also added support for speculative decoding with CudaGraph for LoRA, fixing an issue in vLLM which would capture different CudaGraphs for the base model and adapter. CudaGraphs are important for efficiency since they are used to capture sequences of GPU operations to help reduce GPU kernel overhead, e.g., kernels as a single unit. As a result, CudaGraphs can reduce CPU overheads and these kernel launch latencies. With our execution optimizations, OTPS improved to 50/100 without/with speculative decoding and TTFT improved to 150 ms for GPT-OSS 20B using the default configuration. For the remainder of the blog, we report the numbers with speculative decoding on.
Kernel optimizations
Split-K is a work decomposition strategy that helps improve load balancing for skinny matrices. LoRA shrink computes xA where x has dimension 1×h_in and A has dimension h_in×r. Each of the r output elements requires summing h_in multiplications. Standard GEMM kernels assign different thread groups — batches of GPU threads that share fast on-chip memory — to different output elements, but each thread group computes its h_in summation sequentially. With r in the tens and h_in in the thousands, there are few output elements to parallelize across while each requires a long sequential summation. Split-K addresses this by splitting the summation over the inner dimension K of a GEMM (in this example K=h_in) across multiple thread groups, which compute partial sums in parallel and then combine their results. These partial results require an atomic add to produce the final sum. Since we perform pure atomic addition with no extra logic, we use the Triton compiler freedom for optimizations by setting the parameter sem="relaxed" for the atomic add operation.
The GPU scheduler assigns multiple thread groups to the same output element and runs thread groups for different output elements at the same time. For lora_shrink, each output element requires reading one column of A, which spans the h_in rows. With h_in in the thousands, each column touches cache lines spread across a large memory region. Nearby columns share the same rows and overlap in cache, so thread groups working on neighboring columns can benefit from reusing each other’s loaded data. Cooperative Thread Array (CTA) swizzling reorders the schedule so that thread groups working on nearby columns run at the same time, increasing L2 cache reuse. We applied CTA swizzling to the lora_shrink operation.
We also removed unnecessary masking and dot product operations from the shrink and expand LoRA kernels. Triton kernels load data in fixed-size blocks, but matrix dimensions may not divide evenly into these block sizes. For example, if BLOCK_SIZE_K is 64 but the matrix dimension K is 100, the second block would attempt to read 28 invalid memory locations. Masking helps prevent these illegal memory accesses by checking whether each index is within bounds before loading. However, these conditional checks execute on every load operation, which adds overhead even when the elements are valid. We introduced an EVEN_K parameter that checks whether K divides evenly by BLOCK_SIZE_K. When true, the loads are valid and masking can be skipped entirely, helping reduce both masking overhead and unnecessary dot product computations.
Lastly, we fused the addition of the LoRA weights with the base model weights into the LoRA expand kernel. This optimization helps reduce the kernel launch overhead. These kernel optimizations helped us reach 144 OTPS and 135 ms TTFT for GPT-OSS 20B.
Tuning kernel configurations for Amazon SageMaker AI and Amazon Bedrock
Triton kernels require tuning of parameters such as block sizes (BLOCK_SIZE_M, BLOCK_SIZE_N, BLOCK_SIZE_K), which control how the matrix computation is divided across thread groups. Advanced parameters include GROUP_SIZE_M, which controls thread group ordering for cache locality, and SPLIT_K, which parallelizes summations across the inner matrix dimension.
We found that the MoE LoRA kernels using default configurations optimized for standard fused MoE performed poorly for multi-LoRA serving. These defaults did not account for the additional grid dimension corresponding to the LoRA index and the compound sparsity from multiple adapters. To address this bottleneck, we added support for users to load custom tuned configurations by providing a folder path. For more information, see the vLLM LoRA Tuning documentation. We tuned the four fused_moe_lora operations (gate_up shrink, gate_up expand, down shrink, down expand) simultaneously since they share the same BLOCK_SIZE_M parameter. Amazon SageMaker AI and Bedrock customers now have access to these tuned configurations, which are loaded automatically and achieve 171 OTPS and 124 ms TTFT for GPT-OSS 20B.
Results & Conclusion
Through our collaboration with the vLLM community, we implemented and open-sourced multi-LoRA serving for MoE models including GPT-OSS, Qwen3 MoE, DeepSeek, and Llama MoE. We then applied optimizations, e.g, yielding 454% OTPS improvements and 87% lower TTFT for GPT-OSS 20B in vLLM 0.15.0 vs vLLM 0.11.1rc3. Some optimizations, particularly kernel tuning and CTA swizzling, also improved performance for dense models, e.g., Qwen3 32B OTPS improved by 99%. To leverage this work in your local deployments, use vLLM 0.15.0 or later. Amazon-specific optimizations, available in Amazon Bedrock and Amazon SageMaker AI, help deliver additional latency improvements across models, e.g., 19% faster OTPS and 8% better TTFT vs vLLM 0.15.0 for GPT-OSS 20B. To get started with custom model hosting on Amazon, see the Amazon SageMaker AI hosting and Amazon Bedrock documentation.
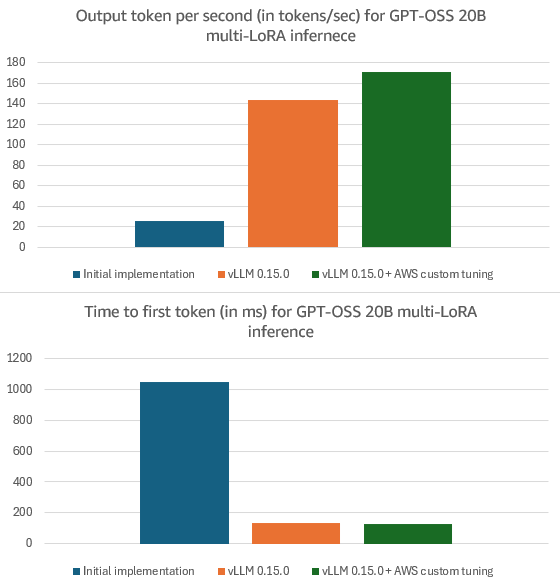
Figure 3: Output tokens per second (OTPS) and time to first token (TTFT) for GPT-OSS 20B multi-LoRA inference: 1/ Initial implementation in vLLM 0.11.1rc3; 2/ with vLLM 0.15.0; 3/ with vLLM 0.15.0 and AWS custom kernel tuning. Experiments used 1600 input tokens and 600 output tokens with LoRA rank 32 and 8 adapters loaded in parallel.
Acknowledgments
We would like to acknowledge the contributors and collaborators from the vLLM community: Jee Li, Chen Wu, Varun Sundar Rabindranath, Simon Mo and Robert Shaw, and our team members: Xin Yang, Sadaf Fardeen, Ashish Khetan, and George Karypis.
About the authors
In this post, we explain how we implemented multi-LoRA inference for Mixture of Experts (MoE) models in vLLM, describe the kernel-level optimizations we performed, and show you how you can benefit from this work. We use GPT-OSS 20B as our primary example throughout this post. Read More