Enterprises are increasingly shifting from relying solely on large, general-purpose language models to developing specialized large language models (LLMs) fine-tuned on their own proprietary data. Although foundation models (FMs) offer impressive general capabilities, they often fall short when applied to the complexities of enterprise environments—where accuracy, security, compliance, and domain-specific knowledge are non-negotiable.
To meet these demands, organizations are adopting cost-efficient models tailored to their internal data and workflows. By fine-tuning on proprietary documents and domain-specific terminology, enterprises are building models that understand their unique context—resulting in more relevant outputs, tighter data governance, and simpler deployment across internal tools.
This shift is also a strategic move to reduce operational costs, improve inference latency, and maintain greater control over data privacy. As a result, enterprises are redefining their AI strategy as customized, right-sized models aligned to their business needs.
Scaling LLM fine-tuning for enterprise use cases presents real technical and operational hurdles, which are being overcome through the powerful partnership between Hugging Face and Amazon SageMaker AI.
Many organizations face fragmented toolchains and rising complexity when adopting advanced fine-tuning techniques like Low-Rank Adaptation (LoRA), QLoRA, and Reinforcement Learning with Human Feedback (RLHF). Additionally, the resource demands of large model training—including memory limitations and distributed infrastructure challenges—often slow down innovation and strains internal teams.
To overcome this, SageMaker AI and Hugging Face have joined forces to simplify and scale model customization. By integrating the Hugging Face Transformers libraries into SageMaker’s fully managed infrastructure, enterprises can now:
- Run distributed fine-tuning jobs out of the box, with built-in support for parameter-efficient tuning methods
- Use optimized compute and storage configurations that reduce training costs and improve GPU utilization
- Accelerate time to value by using familiar open source libraries in a production-grade environment
This collaboration helps businesses focus on building domain-specific, right-sized LLMs, unlocking AI value faster while maintaining full control over their data and models.
In this post, we show how this integrated approach transforms enterprise LLM fine-tuning from a complex, resource-intensive challenge into a streamlined, scalable solution for achieving better model performance in domain-specific applications. We use the meta-llama/Llama-3.1-8B model, and execute a Supervised Fine-Tuning (SFT) job to improve the model’s reasoning capabilities on the MedReason dataset by using distributed training and optimization techniques, such as Fully-Sharded Data Parallel (FSDP) and LoRA with the Hugging Face Transformers library, executed with Amazon SageMaker Training Jobs.
Understanding the core concepts
The Hugging Face Transformers library is an open-source toolkit designed to fine-tune LLMs by enabling seamless experimentation and deployment with popular transformer models.
The Transformers library supports a variety of methods for aligning LLMs to specific objectives, including:
- Thousands of pre-trained models – Access to a vast collection of models like BERT, Meta Llama, Qwen, T5, and more, which can be used for tasks such as text classification, translation, summarization, question answering, object detection, and speech recognition.
- Pipelines API – Simplifies common tasks (such as sentiment analysis, summarization, and image segmentation) by handling tokenization, inference, and output formatting in a single call.
- Trainer API – Provides a high-level interface for training and fine-tuning models, supporting features like mixed precision, distributed training, and integration with popular hardware accelerators.
- Tokenization tools – Efficient and flexible tokenizers for converting raw text into model-ready inputs, supporting multiple languages and formats.
SageMaker Training Jobs is a fully managed, on-demand machine learning (ML) service that runs remotely on AWS infrastructure to train a model using your data, code, and chosen compute resources. This service abstracts away the complexities of provisioning and managing the underlying infrastructure, so you can focus on developing and fine-tuning your ML and foundation models. Key capabilities offered by SageMaker training jobs are:
- Fully managed – SageMaker handles resource provisioning, scaling, and management for your training jobs, so you don’t need to manually set up servers or clusters.
- Flexible input – You can use built-in algorithms, pre-built containers, or bring your own custom training scripts and Docker containers, to execute training workloads with most popular frameworks such as the Hugging Face Transformers library.
- Scalable – It supports single-node or distributed training across multiple instances, making it suitable for both small and large-scale ML workloads.
- Integration with multiple data sources – Training data can be stored in Amazon Simple Storage Service (Amazon S3), Amazon FSx, and Amazon Elastic Block Store (Amazon EBS), and output model artifacts are saved back to Amazon S3 after training is complete.
- Customizable – You can specify hyperparameters, resource types (such as GPU or CPU instances), and other settings for each training job.
- Cost-efficient options – Features like managed Spot Instances, flexible training plans, and heterogeneous clusters help optimize training costs.
Solution overview
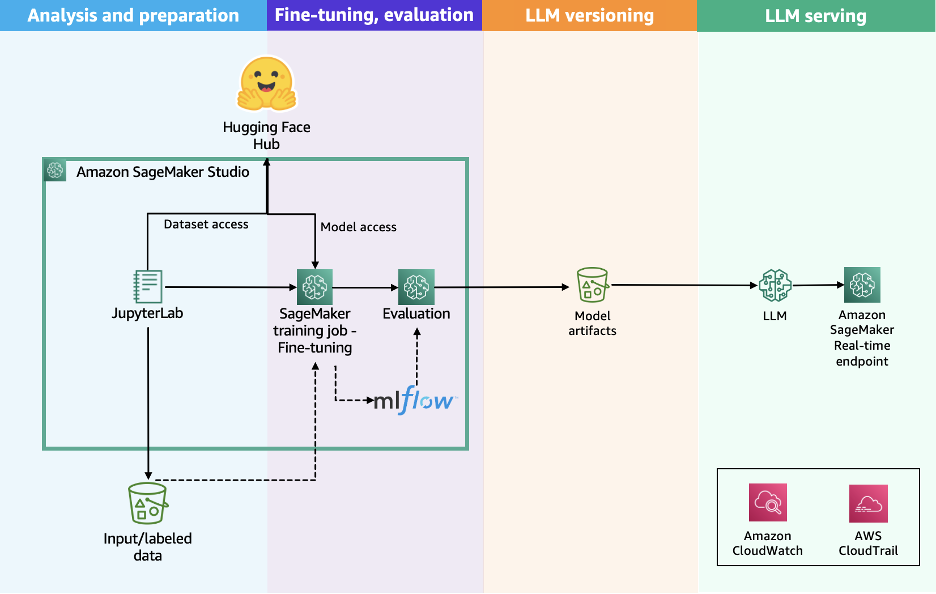
The following diagram illustrates the solution workflow of using the Hugging Face Transformers library with a SageMaker Training job.
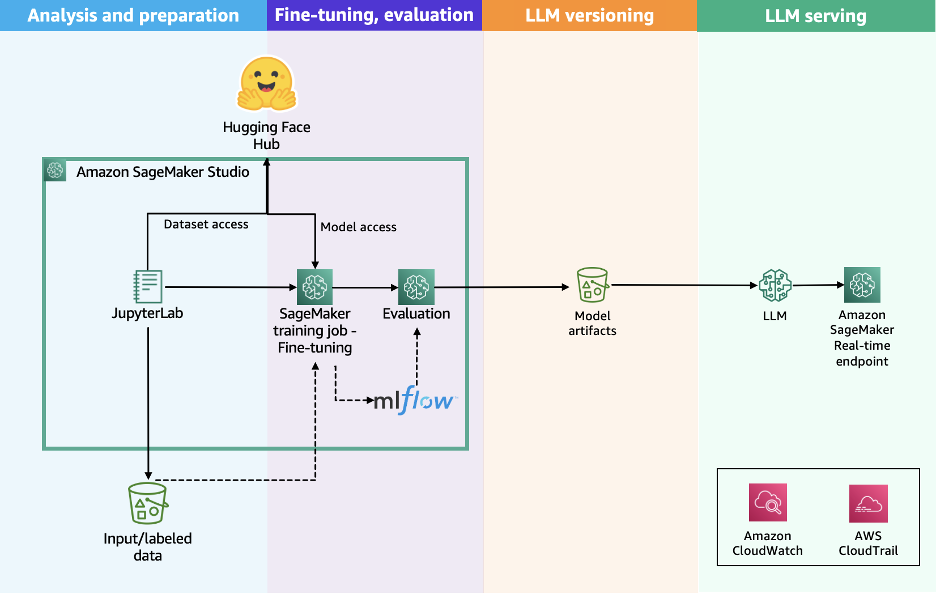
The workflow consists of the following steps:
- The user prepares the dataset by formatting it with the specific prompt style used for the selected model.
- The user prepares the training script by using the Hugging Face Transformers library to start the training workload, by specifying the configuration for the distribution option selected, such as Distributed Data Parallel (DDP) or Fully-Sharded Data Parallel (FSDP).
- The user submits an API request to SageMaker AI, passing the location of the training script, the Hugging Face Training container URI, and the training configurations required, such as distribution algorithm, instance type, and instance count.
- SageMaker AI uses the training job launcher script to run the training workload on a managed compute cluster. Based on the selected configuration, SageMaker AI provisions the required infrastructure, orchestrates distributed training, and upon completion, automatically decommissions the cluster.
This streamlined architecture delivers a fully managed user experience, helping you quickly develop your training code, define training parameters, and select your preferred infrastructure. SageMaker AI handles the end-to-end infrastructure management with a pay-as-you-go pricing model that bills only for the net training time in seconds.
Prerequisites
You must complete the following prerequisites before you can run the Meta Llama 3.1 8B fine-tuning notebook:
- Make the following quota increase requests for SageMaker AI. For this use case, you will need to request a minimum of 1 p4d.24xlarge instance (with 8 x NVIDIA A100 GPUs) and scale to more p4d.24xlarge instances (depending on time-to-train and cost-to-train trade-offs for your use case). To help determine the right cluster size for the fine-tuning workload, you can use tools like VRAM Calculator or “Can it run LLM“. On the Service Quotas console, request the following SageMaker AI quotas:
- P4D instances (
p4.24xlarge) for training job usage: 1
- P4D instances (
- Create an AWS Identity and Access Management (IAM) role with managed policies
AmazonSageMakerFullAccessandAmazonS3FullAccessto give required access to SageMaker AI to run the examples. - Assign the following policy as a trust relationship to your IAM role:
- (Optional) Create an Amazon SageMaker Studio domain (refer to Use quick setup for Amazon SageMaker AI) to access Jupyter notebooks with the preceding role. You can also use JupyterLab in your local setup
These permissions grant broad access and are not recommended for use in production environments. See the SageMaker Developer Guide for guidance on defining more fine-grained permissions.
Prepare the dataset
To prepare the dataset, you must load the UCSC-VLAA/MedReason dataset. MedReason is a large-scale, high-quality medical reasoning dataset designed to enable faithful and explainable medical problem-solving in LLMs. The following table shows an example of the data.
| dataset_name | id_in_dataset | question | answer | reasoning | options |
|---|---|---|---|---|---|
| medmcqa | 7131 | Urogenital Diaphragm is made up of the following… | Colle’s fascia. Explanation: Colle’s fascia do… | Finding reasoning paths:n1. Urogenital diaphr… | Answer Choices:nA. Deep transverse Perineusn… |
| medmcqa | 7133 | Child with Type I Diabetes. What is the advise… | After 5 years. Explanation: Screening for diab… | **Finding reasoning paths:**nn1. Type 1 Diab… | Answer Choices:nA. After 5 yearsnB. After 2 … |
| medmcqa | 7134 | Most sensitive test for H pylori is- |
Biopsy urease test. Explanation: Davidson&… |
**Finding reasoning paths:**nn1. Consider th… | Answer Choices:nA. Fecal antigen testnB. Bio… |
We want to use the following columns for preparing our dataset:
- question – The question being posed
- answer – The correct answer to the question
- reasoning – A detailed, step-by-step logical explanation of how to arrive at the correct answer
We can use the following steps to format the input in the proper style used for Meta Llama 3.1, and configure the data channels for SageMaker training jobs on Amazon S3:
- Load the UCSC-VLAA/MedReason dataset, using the first 10,000 rows of the original dataset:
from datasets import load_dataset dataset = load_dataset("UCSC-VLAA/MedReason", split="train[:10000]") - Apply the proper chat template to the dataset by using the
apply_chat_templatemethod of the Tokenizer:The function
prepare_datasetwill iterate over the elements of the dataset, and use theapply_chat_templatefunction to have a prompt template in the following form:The following code is an example of the formatted prompt:
- Split the dataset into train, validation, and test datasets:
- Prepare the training and validation datasets for the SageMaker training job by saving them as JSON files and constructing the S3 paths where these files will be uploaded:
Prepare the training script
To fine-tune meta-llama/Llama-3.1-8B with a SageMaker Training job, we prepared the train.py file, which serves as the entry point of the training job to execute the fine-tuning workload.
The training process can use Trainer or SFTTrainer classes to fine-tune our model. This simplifies the process of continued pre-training for LLMs. This approach makes fine-tuning efficient for adapting pre-trained models to specific tasks or domains.
The Trainer and SFTTrainer classes both facilitate model training with Hugging Face transformers. The Trainer class is the standard high-level API for training and evaluating transformer models on a wide range of tasks, including text classification, sequence labeling, and text generation. The SFTTrainer is a subclass built specifically for supervised fine-tuning of LLMs, particularly for instruction-following or conversational tasks.
To accelerate the model fine-tuning, we distribute the training workload by using the FSDP technique. It is an advanced parallelism technique designed to train large models that might not fit in the memory of a single GPU, with the following benefits:
- Parameter sharding – Instead of replicating the entire model on each GPU, FSDP splits (shards) model parameters, optimizer states, and gradients across GPUs
- Memory efficiency – By sharding, FSDP drastically reduces the memory footprint on each device, enabling training of larger models or larger batch sizes
- Synchronization – During training, FSDP gathers only the necessary parameters for each computation step, then releases memory immediately after, further saving resources
- CPU offload – Optionally, FSDP can offload some data to CPUs to save even more GPU memory
- In our example, we use the
Trainerclass and define the requiredTrainingArgumentsto execute the FSDP distributed workload: - To further optimize the fine-tuning workload, we use the QLoRA technique, which quantizes a pre-trained language model to 4 bits and attaches small Low-Rank Adapters, which are fine-tuned:
- The
script_argsandtraining_argsare provided as hyperparameters for the SageMaker Training job in a configuration recipe.yamlfile and parsed in thetrain.pyfile by using theTrlParserclass provided by Hugging Face TRL:For the implemented use case, we decided to fine-tune the adapter with the following values:
- lora_r: 32 – Allows the adapter to capture more complex reasoning transformations.
- lora_alpha: 64 – Given the reasoning task we are trying to improve, this value allows the adapter to have a significant impact to the base.
- lora_dropout: 0.05 – We want to preserve reasoning connection by avoiding breaking important ones.
- warmup_steps: 100 – Gradually increases the learning rate to the specified value. For this reasoning task, we want the model to learn a new structure without forgetting the previous knowledge.
- weight_decay: 0.01 – Maintains model generalization.
- Prepare the configuration file for the SageMaker Training job by saving them as JSON files and constructing the S3 paths where these files will be uploaded:
SFT training using a SageMaker Training job
To run a fine-tuning workload using the SFT training script and SageMaker Training jobs, we use the ModelTrainer class.
The ModelTrainer class is a and more intuitive approach to model training that significantly enhances user experience and supports distributed training, Build Your Own Container (BYOC), and recipes. For additional information refer to the SageMaker Python SDK documentation.
Set up the fine-tuning workload with the following steps:
- Specify the instance type, the container image for the training job, and the checkpoint path where the model will be stored:
- Define the source code configuration by pointing to the created
train.py: - Configure the training compute by optionally providing the parameter
keep_alive_period_in_secondsto use managed warm pools, to retain and reuse the cluster during the experimentation phase: - Create the
ModelTrainerfunction by providing the required training setup, and define the argumentdistributed=Torchrun()to use torchrun as a launcher to execute the training job in a distributed manner across the available GPUs in the selected instance: - Set up the input channels for the
ModelTrainerby creatingInputDataobjects from the provided S3 bucket paths for the training and validation dataset, and for the configuration parameters: - Submit the training job:
The training job with Flash Attention 2 for one epoch with a dataset of 10,000 samples takes approximately 18 minutes to complete.
Deploy and test fine-tuned Meta Llama 3.1 8B on SageMaker AI
To evaluate your fine-tuned model, you have several options. You can use an additional SageMaker Training job to evaluate the model with Hugging Face Lighteval on SageMaker AI, or you can deploy the model to a SageMaker real-time endpoint and interactively test the model by using techniques like LLM as judge to compare generated content with ground truth content. For a more comprehensive evaluation that demonstrates the impact of fine-tuning on model performance, you can use the MedReason evaluation script to compare the base meta-llama/Llama-3.1-8B model with your fine-tuned version.
In this example, we use the deployment approach, iterating over the test dataset and evaluating the model on those samples using a simple loop.
- Select the instance type and the container image for the endpoint:
- Create the SageMaker Model using the container URI for vLLM and the S3 path to your model. Set your vLLM configuration, including the number of GPUs and max input tokens. For a full list of configuration options, see vLLM engine arguments.
- Create the endpoint configuration by specifying the type and number of instances:
- Deploy the model:
SageMaker AI will now create the endpoint and deploy the model to it. This can take 5–10 minutes. Afterwards, you can test the model by sending some example inputs to the endpoint. You can use the invoke_endpoint method of the sagemaker-runtime client to send the input to the model and get the output:
The following are some examples of generated answers:
The fine-tuned model shows strong reasoning capabilities by providing structured, detailed explanations with clear thought processes, breaking down the concepts step-by-step before arriving at the final answer. This example showcases the effectiveness of our fine-tuning approach using Hugging Face Transformers and a SageMaker Training job.
Clean up
To clean up your resources to avoid incurring additional charges, follow these steps:
- Delete any unused SageMaker Studio resources.
- (Optional) Delete the SageMaker Studio domain.
- Verify that your training job isn’t running anymore. To do so, on the SageMaker console, under Training in the navigation pane, choose Training jobs.
- Delete the SageMaker endpoint.
Conclusion
In this post, we demonstrated how enterprises can efficiently scale fine-tuning of both small and large language models by using the integration between the Hugging Face Transformers library and SageMaker Training jobs. This powerful combination transforms traditionally complex and resource-intensive processes into streamlined, scalable, and production-ready workflows.
Using a practical example with the meta-llama/Llama-3.1-8B model and the MedReason dataset, we demonstrated how to apply advanced techniques like FSDP and LoRA to reduce training time and cost—without compromising model quality.
This solution highlights how enterprises can effectively address common LLM fine-tuning challenges such as fragmented toolchains, high memory and compute requirements, and multi-node scaling inefficiencies and GPU underutilization.
By using the integrated Hugging Face and SageMaker architecture, businesses can now build and deploy customized, domain-specific models faster—with greater control, cost-efficiency, and scalability.
To get started with your own LLM fine-tuning project, explore the code samples provided in our GitHub repository.
About the Authors
 Florent Gbelidji is a Machine Learning Engineer for Customer Success at Hugging Face. Based in Paris, France, Florent joined Hugging Face 3.5 years ago as an ML Engineer in the Expert Acceleration Program, helping companies build solutions with open source AI. He is now the Cloud Partnership Tech Lead for the AWS account, driving integrations between the Hugging Face environment and AWS services.
Florent Gbelidji is a Machine Learning Engineer for Customer Success at Hugging Face. Based in Paris, France, Florent joined Hugging Face 3.5 years ago as an ML Engineer in the Expert Acceleration Program, helping companies build solutions with open source AI. He is now the Cloud Partnership Tech Lead for the AWS account, driving integrations between the Hugging Face environment and AWS services.
 Bruno Pistone is a Senior Worldwide Generative AI/ML Specialist Solutions Architect at AWS based in Milan, Italy. He works with AWS product teams and large customers to help them fully understand their technical needs and design AI and machine learning solutions that take full advantage of the AWS cloud and Amazon ML stack. His expertise includes distributed training and inference workloads, model customization, generative AI, and end-to-end ML. He enjoys spending time with friends, exploring new places, and traveling to new destinations.
Bruno Pistone is a Senior Worldwide Generative AI/ML Specialist Solutions Architect at AWS based in Milan, Italy. He works with AWS product teams and large customers to help them fully understand their technical needs and design AI and machine learning solutions that take full advantage of the AWS cloud and Amazon ML stack. His expertise includes distributed training and inference workloads, model customization, generative AI, and end-to-end ML. He enjoys spending time with friends, exploring new places, and traveling to new destinations.
 Louise Ping is a Senior Worldwide GenAI Specialist, where she helps partners build go-to-market strategies and leads cross-functional initiatives to expand opportunities and drive adoption. Drawing from her diverse AWS experience across Storage, APN Partner Marketing, and AWS Marketplace, she works closely with strategic partners like Hugging Face to drive technical collaborations. When not working at AWS, she attempts home improvement projects—ideally with limited mishaps.
Louise Ping is a Senior Worldwide GenAI Specialist, where she helps partners build go-to-market strategies and leads cross-functional initiatives to expand opportunities and drive adoption. Drawing from her diverse AWS experience across Storage, APN Partner Marketing, and AWS Marketplace, she works closely with strategic partners like Hugging Face to drive technical collaborations. When not working at AWS, she attempts home improvement projects—ideally with limited mishaps.
 Safir Alvi is a Worldwide GenAI/ML Go-To-Market Specialist at AWS based in New York. He focuses on advising strategic global customers on scaling their model training and inference workloads on AWS, and driving adoption of Amazon SageMaker AI Training Jobs and Amazon SageMaker HyperPod. He specializes in optimizing and fine-tuning generative AI and machine learning models across diverse industries, including financial services, healthcare, automotive, and manufacturing.
Safir Alvi is a Worldwide GenAI/ML Go-To-Market Specialist at AWS based in New York. He focuses on advising strategic global customers on scaling their model training and inference workloads on AWS, and driving adoption of Amazon SageMaker AI Training Jobs and Amazon SageMaker HyperPod. He specializes in optimizing and fine-tuning generative AI and machine learning models across diverse industries, including financial services, healthcare, automotive, and manufacturing.
In this post, we show how this integrated approach transforms enterprise LLM fine-tuning from a complex, resource-intensive challenge into a streamlined, scalable solution for achieving better model performance in domain-specific applications. Read More