Retrieval Augmented Generation (RAG) has become a crucial technique for improving the accuracy and relevance of AI-generated responses. The effectiveness of RAG heavily depends on the quality of context provided to the large language model (LLM), which is typically retrieved from vector stores based on user queries. The relevance of this context directly impacts the model’s ability to generate accurate and contextually appropriate responses.
One effective way to improve context relevance is through metadata filtering, which allows you to refine search results by pre-filtering the vector store based on custom metadata attributes. By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content.
In some use cases, particularly those involving complex user queries or a large number of metadata attributes, manually constructing metadata filters can become challenging and potentially error-prone. To address these challenges, you can use LLMs to create a robust solution. This approach, which we call intelligent metadata filtering, uses tool use (also known as function calling) to dynamically extract metadata filters from natural language queries. Function calling allows LLMs to interact with external tools or functions, enhancing their ability to process and respond to complex queries.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. One of its key features, Amazon Bedrock Knowledge Bases, allows you to securely connect FMs to your proprietary data using a fully managed RAG capability and supports powerful metadata filtering capabilities.
In this post, we explore an innovative approach that uses LLMs on Amazon Bedrock to intelligently extract metadata filters from natural language queries. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries. This approach can also enhance the quality of retrieved information and responses generated by the RAG applications.
This approach not only addresses the challenges of manual metadata filter construction, but also demonstrates how you can use Amazon Bedrock to create more effective and user-friendly RAG applications.
Understanding metadata filtering
Metadata filtering is a powerful feature that allows you to refine search results by pre-filtering the vector store based on custom metadata attributes. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information. For a comprehensive overview of metadata filtering and its benefits, refer to Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy.
The importance of context quality in RAG applications
In RAG applications, the accuracy and relevance of generated responses heavily depend on the quality of the context provided to the LLM. This context, typically retrieved from the knowledge base based on user queries, directly impacts the model’s ability to generate accurate and contextually appropriate outputs.
To evaluate the effectiveness of a RAG system, we focus on three key metrics:
Answer relevancy – Measures how well the generated answer addresses the user’s query. By improving the relevance of the retrieved context through dynamic metadata filtering, you can significantly enhance the answer relevancy.
Context recall – Assesses the proportion of relevant information retrieved from the knowledge base. Dynamic metadata filtering helps improve context recall by more accurately identifying and retrieving the most pertinent documents or passages for a given query.
Context precision – Evaluates the accuracy of the retrieved context, making sure the information provided to the LLM is highly relevant to the query. Dynamic metadata filtering enhances context precision by reducing the inclusion of irrelevant or tangentially related information.
By implementing dynamic metadata filtering, you can significantly improve these metrics, leading to more accurate and relevant RAG responses. Let’s explore how to implement this approach using Amazon Bedrock and Pydantic.
Solution overview
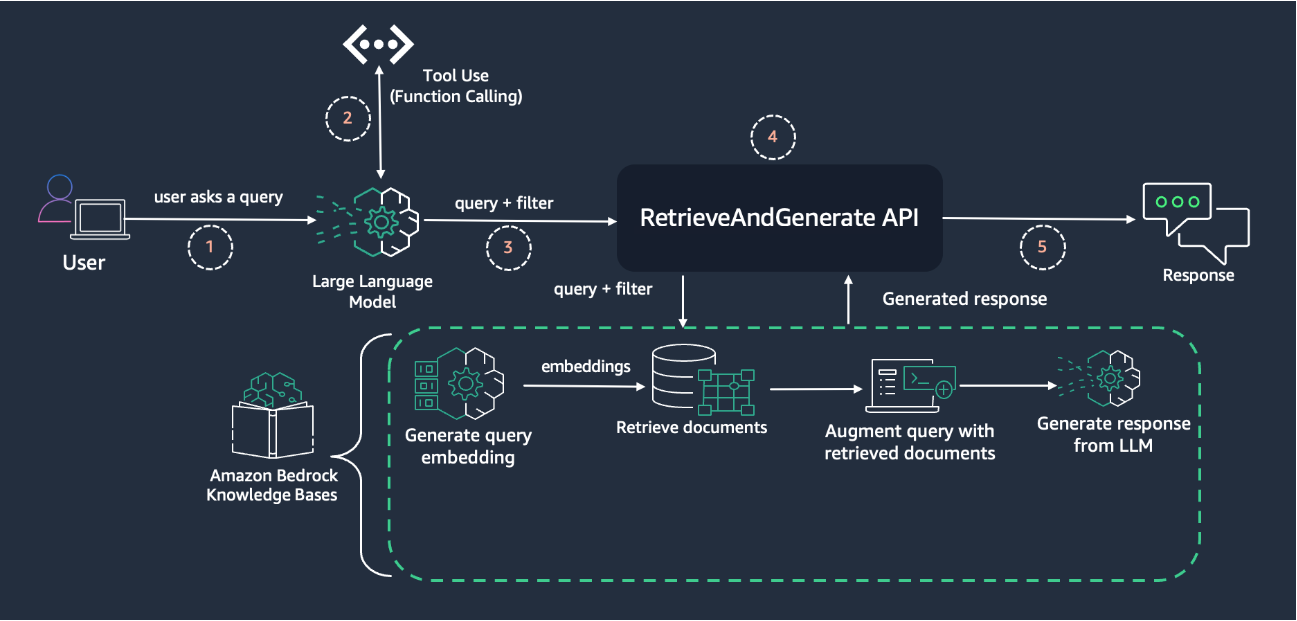
In this section, we illustrate the flow of the dynamic metadata filtering solution using the tool use (function calling) capability. The following diagram illustrates high level RAG architecture with dynamic metadata filtering.
The process consists of the following steps:
The process begins when a user asks a query through their interface.
The user’s query is first processed by an LLM using the tool use (function calling) feature. This step is crucial for extracting relevant metadata from the natural language query. The LLM analyzes the query and identifies key entities or attributes that can be used for filtering.
The extracted metadata is used to construct an appropriate metadata filter. This combined query and filter is passed to the RetrieveAndGenerate
This API, part of Amazon Bedrock Knowledge Bases, handles the core RAG workflow. It consists of several sub-steps:
The user query is converted into a vector representation (embedding).
Using the query embedding and the metadata filter, relevant documents are retrieved from the knowledge base.
The original query is augmented with the retrieved documents, providing context for the LLM.
The LLM generates a response based on the augmented query and retrieved context.
Finally, the generated response is returned to the user.
This architecture uses the power of tool use for intelligent metadata extraction from a user’s query, combined with the robust RAG capabilities of Amazon Bedrock Knowledge Bases. The key innovation lies in Step 2, where the LLM is used to dynamically interpret the user’s query and extract relevant metadata for filtering. This approach allows for more flexible and intuitive querying, because users can express their information needs in natural language without having to manually specify metadata filters.
The subsequent steps (3–4) follow a more standard RAG workflow, but with the added benefit of using the dynamically generated metadata filter to improve the relevance of retrieved documents. This combination of intelligent metadata extraction and traditional RAG techniques results in more accurate and contextually appropriate responses to user queries.
Prerequisites
Before proceeding with this tutorial, make sure you have the following in place:
AWS account – You should have an AWS account with access to Amazon Bedrock.
Model access – Amazon Bedrock users need to request access to FMs before they’re available for use. For this solution, you need to enable access to the Amazon Titan Embeddings G1 – Text and Anthropic’s Claude Instant 1.2 model in Amazon Bedrock. For more information, refer to Access Amazon Bedrock foundation models.
Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata. For detailed instructions on setting up a knowledge base, including data preparation, metadata creation, and step-by-step guidance, refer to Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy. This post walks you through the entire process of creating a knowledge base and ingesting data with metadata.
In the following sections, we explore how to implement dynamic metadata filtering using the tool use feature in Amazon Bedrock and Pydantic for data validation.
Tool use is a powerful feature in Amazon Bedrock that allows models to access external tools or functions to enhance their response generation capabilities. When you send a message to a model, you can provide definitions for one or more tools that could potentially help the model generate a response. If the model determines it needs a tool, it responds with a request for you to call the tool, including the necessary input parameters.
In our example, we use Amazon Bedrock to extract entities like genre and year from natural language queries about video games. For a query like “A strategy game with cool graphics released after 2023?”” it will extract “strategy” (genre) and “2023” (year). These extracted entities will then dynamically construct metadata filters to retrieve only relevant games from the knowledge base. This allows flexible, natural language querying with precise metadata filtering.
Set up the environment
First, set up your environment with the necessary imports and Boto3 clients:
Define Pydantic models
For this solution, you use Pydantic models to validate and structure our extracted entities:
Implement entity extraction using tool use
You now define a tool for entity extraction with basic instructions and use it with Amazon Bedrock. You should use a proper description for this to work for your use case:
Construct a metadata filter
Create a function to construct the metadata filter based on the extracted entities:
Create the main function
Finally, create a main function to process the query and retrieve results:
This implementation uses the tool use feature in Amazon Bedrock to dynamically extract entities from user queries. It then uses these entities to construct metadata filters, which are applied when retrieving results from the knowledge base.
The key advantages of this approach include:
Flexibility – The system can handle a wide range of natural language queries without predefined patterns
Accuracy – By using LLMs for entity extraction, you can capture nuanced information from user queries
Extensibility – You can expand the tool definition to extract additional metadata fields as needed
Handling edge cases
When implementing dynamic metadata filtering, it’s important to consider and handle edge cases. In this section, we discuss some ways you can address them.
If the tool use process fails to extract metadata from the user query due to an absence of filters or errors, you have several options:
Proceed without filters – This allows for a broad search, but may reduce precision:
Apply a default filter – This can help maintain some level of filtering even when no specific metadata is extracted:
Use the most common filter – If you have analytics on common user queries, you could apply the most frequently used filter
Strict policy handling – For cases where you want to enforce stricter policies or adhere to specific responsible AI guidelines, you might choose not to process queries that don’t yield metadata:
This approach makes sure that only queries with clear, extractable metadata are processed, potentially reducing errors and improving overall response quality.
Performance considerations
The dynamic approach introduces an additional FM call to extract metadata, which will increase both cost and latency. To mitigate this, consider the following:
Use a faster, lighter FM for the metadata extraction step. This can help reduce latency and cost while still providing accurate entity extraction.
Implement caching mechanisms for common queries to help avoid redundant FM calls.
Monitor and optimize the performance of your metadata extraction model regularly.
Clean up
After you’ve finished experimenting with this solution, it’s crucial to clean up your resources to avoid unnecessary charges. For detailed cleanup instructions, see Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy. These steps will guide you through deleting your knowledge base, vector database, AWS Identity and Access Management (IAM) roles, and sample datasets, making sure that you don’t incur unexpected costs.
Conclusion
By implementing dynamic metadata filtering using Amazon Bedrock and Pydantic, you can significantly enhance the flexibility and power of RAG applications. This approach allows for more intuitive querying of knowledge bases, leading to improved context recall and more relevant AI-generated responses.
As you explore this technique, remember to balance the benefits of dynamic filtering against the additional computational costs. We encourage you to try this method in your own RAG applications and share your experiences with the community.
For additional resources, refer to the following:
Retrieve data and generate AI responses with knowledge bases
Use RAG to improve responses in generative AI applications
Amazon Bedrock Knowledge Bases – Samples for building RAG workflows
Happy building with Amazon Bedrock!
About the Authors
Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High-Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
Ishan Singh is a Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in machine learning and natural language processing, Ishan specializes in developing safe and responsible AI systems that drive business value. Outside of work, he enjoys playing competitive volleyball, exploring local bike trails, and spending time with his wife and dog, Beau.
In this post, we explore an innovative approach that uses LLMs on Amazon Bedrock to intelligently extract metadata filters from natural language queries. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries. This approach can also enhance the quality of retrieved information and responses generated by the RAG applications. Read More