This post is co-written with Less Wright and Wei Feng from Meta
Pre-training large language models (LLMs) is the first step in developing powerful AI systems that can understand and generate human-like text. By exposing models to vast amounts of diverse data, pre-training lays the groundwork for LLMs to learn general language patterns, world knowledge, and reasoning capabilities. This foundational process enables LLMs to perform a wide range of tasks without task-specific training, making them highly versatile and adaptable. Pre-training is essential for building a strong base of knowledge, which can then be refined and specialized through fine-tuning, transfer learning, or few-shot learning approaches.
In this post, we collaborate with the team working on PyTorch at Meta to showcase how the torchtitan library accelerates and simplifies the pre-training of Meta Llama 3-like model architectures. We showcase the key features and capabilities of torchtitan such as FSDP2, torch.compile integration, and FP8 support that optimize the training efficiency. We pre-train a Meta Llama 3 8B model architecture using torchtitan on Amazon SageMaker on p5.48xlarge instances, each equipped with 8 Nvidia H100 GPUs. We demonstrate a 38.23% performance speedup in the training throughput compared to the baseline without applying the optimizations (as shown in the following figure). Amazon SageMaker Model Training reduces the time and cost to train and tune machine learning (ML) models at scale without the need to manage infrastructure. You can take advantage of the highest-performing ML compute infrastructure currently available, and SageMaker can automatically scale infrastructure up or down, from one to thousands of GPUs.
To learn more, you can find our complete code sample on GitHub.
Introduction to torchtitan
torchtitan is a reference architecture for large-scale LLM training using native PyTorch. It aims to showcase PyTorch’s latest distributed training features in a clean, minimal code base. The library is designed to be simple to understand, use, and extend for different training purposes, with minimal changes required to the model code when applying various parallel processing techniques.
torchtitan offers several key features, including FSDP2 with per-parameter sharding, tensor parallel processing, selective layer and operator activation checkpointing, and distributed checkpointing. It supports pre-training of Meta Llama 3-like and Llama 2-like model architectures of various sizes and includes configurations for multiple datasets. The library provides straightforward configuration through TOML files and offers performance monitoring through TensorBoard. In the following sections, we highlight some of the key features of torchtitan.
Transitioning from FSDP1 to FSDP2
FSDP1 and FSDP2 are two approaches to fully sharded data parallel training. FSDP1 uses flat-parameter sharding, which flattens all parameters to 1D, concatenates them into a single tensor, pads it, and then chunks it across workers. This method offers bounded padding and efficient unsharded storage, but might not always allow optimal sharding for individual parameters. FSDP2, on the other hand, represents sharded parameters as DTensors sharded on dim-0, handling each parameter individually. This approach enables easier manipulation of parameters, for example per-weight learning rate, communication-free sharded state dicts, and simpler meta-device initialization. The transition from FSDP1 to FSDP2 reflects a shift towards more flexible and efficient parameter handling in distributed training, addressing limitations of the flat-parameter approach while potentially introducing new optimization opportunities.
torchtitan support for torch.compile
torch.compile is a key feature in PyTorch that significantly boosts model performance with minimal code changes. Through its just-in-time (JIT) compilation, it analyzes and transforms PyTorch code into more efficient kernels. torchtitan supports torch.compile, which delivers substantial speedups, especially for large models and complex architectures, by using techniques like operator fusion, memory planning, and automatic kernel selection. This is enabled by setting compile = true in the model’s TOML configuration file.
torchtitan support for FP8 linear operations
torchtitan provides support for FP8 (8-bit floating point) computation that significantly reduces memory footprint and enhances performance in LLM training. FP8 has two formats, E4M3 and E5M2, each optimized for different aspects of training. E4M3 offers higher precision, making it ideal for forward propagation, whereas E5M2, with its larger dynamic range, is better suited for backpropagation. When operating at a lower precision, FP8 has no impact on model accuracy, which we demonstrate by convergence comparisons of the Meta Llama 3 8B pre-training at 2,000 steps. FP8 support on torchtitan is through the torchao library, and we enable FP8 by setting enable_float8_linear = true in the model’s TOML configuration file.
torchtitan support for FP8 all-gather
This feature enables efficient communication of FP8 tensors across multiple GPUs, significantly reducing network bandwidth compared to bfloat16 all-gather operations. FP8 all-gather performs float8 casting before the all-gather operation, reducing the message size. Key to its efficiency is the combined absolute maximum (AMAX) AllReduce, which calculates AMAX for all float8 parameters in a single operation after the optimizer step, avoiding multiple small all-reduces. Similar to FP8 support, this also has no impact on model accuracy, which we demonstrate by convergence comparisons of the Meta Llama 3 8B pre-training.
Pre-training Meta Llama 3 8B with torchtitan on Amazon SageMaker
SageMaker training jobs offer several key advantages that enhance the pre-training process of Meta Llama 3-like model architectures with torchtitan. It provides a fully managed environment that simplifies large-scale distributed training across multiple instances, which is crucial for efficiently pre-training LLMs. SageMaker supports custom containers, which allows seamless integration of the torchtitan library and its dependencies, so all necessary components are readily available.
The built-in distributed training capabilities of SageMaker streamline the setup of multi-GPU and multi-node jobs, reducing the complexity typically associated with such configurations. Additionally, SageMaker integrates with TensorBoard, enabling real-time monitoring and visualization of training metrics and providing valuable insights into the pre-training process. With these features, researchers and practitioners can focus more on model development and optimization rather than infrastructure management, ultimately accelerating the iterative process of creating and refining custom LLMs.
Solution overview
In the following sections, we walk you through how to prepare a custom image with the torchtitan library, then configure a training job estimator function to launch a Meta Llama 3 8B model pre-training with the c4 dataset (Colossal Clean Crawled Corpus) on SageMaker. The c4 dataset is a large-scale web text corpus that has been cleaned and filtered to remove low-quality content. It is frequently used for pre-training language models.
Prerequisites
Before you begin, make sure you have the following requirements in place:
An AWS account.
A SageMaker domain and Amazon SageMaker Studio For instructions to create these, refer to Quick setup to Amazon SageMaker.
A Hugging Face access token so you can download the Meta Llama 3 models and tokenizer to use later.
You need to request a quota increase of at least 1 ml.p5.48xlarge instance for training job usage on SageMaker.
Build the torchtitan custom image
SageMaker BYOC (Bring Your Own Container) allows you to use custom Docker containers to train and deploy ML models. Typically, SageMaker provides built-in algorithms and preconfigured environments for popular ML frameworks. However, there may be cases where you have unique or proprietary algorithms, dependencies, or specific requirements that aren’t available in the built-in options, necessitating custom containers. In this case, we need to use the nightly versions of torch, torchdata, and the torchao package to train with FP8 precision.
We use the Amazon SageMaker Studio Image Build convenience package, which offers a command line interface (CLI) to simplify the process of building custom container images directly from SageMaker Studio notebooks. This tool eliminates the need for manual setup of Docker build environments, streamlining the workflow for data scientists and developers. The CLI automatically manages the underlying AWS services required for image building, such as Amazon Simple Storage Service (Amazon S3), AWS CodeBuild, and Amazon Elastic Container Registry (Amazon ECR), allowing you to focus on your ML tasks rather than infrastructure setup. It offers a simple command interface, handles packaging of Dockerfiles and container code, and provides the resulting image URI for use in SageMaker training and hosting.
Before getting started, make sure your AWS Identity and Access Management (IAM) execution role has the required IAM permissions and policies to use the Image Build CLI. For more information, see Using the Amazon SageMaker Studio Image Build CLI to build container images from your Studio notebooks. We have provided the Jupyter notebook to build the custom container in the GitHub repo.
Complete the following steps to build the custom image:
Install the Image Build package with the following command:
To extend the pre-built image, you can use the included deep learning libraries and settings without having to create an image from scratch:
Next, specify the libraries to install. You need the nightly versions of torch, torchdata, and the torchao libraries:
Use the Image Build CLI to build and push the image to Amazon ECR:
!sm-docker build –repository torchtitan:latest . You’re now ready to use this image for pre-training models with torchtitan in SageMaker.
Prepare your dataset (optional)
By default, the torchtitan library uses the allenai/c4 “en” dataset in its training configuration. This is streamed directly during training using the HuggingFaceDataset class. However, you may want to pre-train the Meta Llama 3 models on your own dataset residing in Amazon S3. For this purpose, we have prepared a sample Jupyter notebook to download the allenai/c4 “en” dataset from the Hugging Face dataset hub to an S3 bucket. We use the SageMaker InputDataConfiguration to load the dataset to our training instances in the later section. You can download the dataset with a SageMaker processing job available in the sample Jupyter notebook.
Launch your training with torchtitan
Complete the following steps to launch your training:
Import the necessary SageMaker modules and retrieve your work environment details, such as AWS account ID and AWS Region. Make sure to upgrade the SageMaker SDK to the latest version. This might require a SageMaker Studio kernel restart.
Clone the torchtitan repository and prepare the training environment. Create a source directory and move the necessary dependencies from the torchtitan directory. This step makes sure you have all the required files for your training process.
Use the following command to download the Meta Llama 3 tokenizer, which is essential for preprocessing your dataset. Provide your Hugging Face token.
One of the key advantages of torchtitan is its straightforward configuration through TOML files. We modify the Meta Llama-3-8b TOML configuration file to enable monitoring and optimization features.
Enable TensorBoard profiling for better insights into the training process:
Enable torch.compile for improved performance:
Enable FP8 for more efficient computations:
Activate FP8 all-gather for optimized distributed training:
To monitor the training progress, set up TensorBoard output. This allows you to visualize the training metrics in real time, providing valuable insights into how the model is learning.
Set up the data channels for SageMaker training. Create TrainingInput objects that point to the preprocessed dataset in Amazon S3, so your model has access to the training data it needs.
Initiate the model training on SageMaker:
estimator.fit(inputs=data_channels)
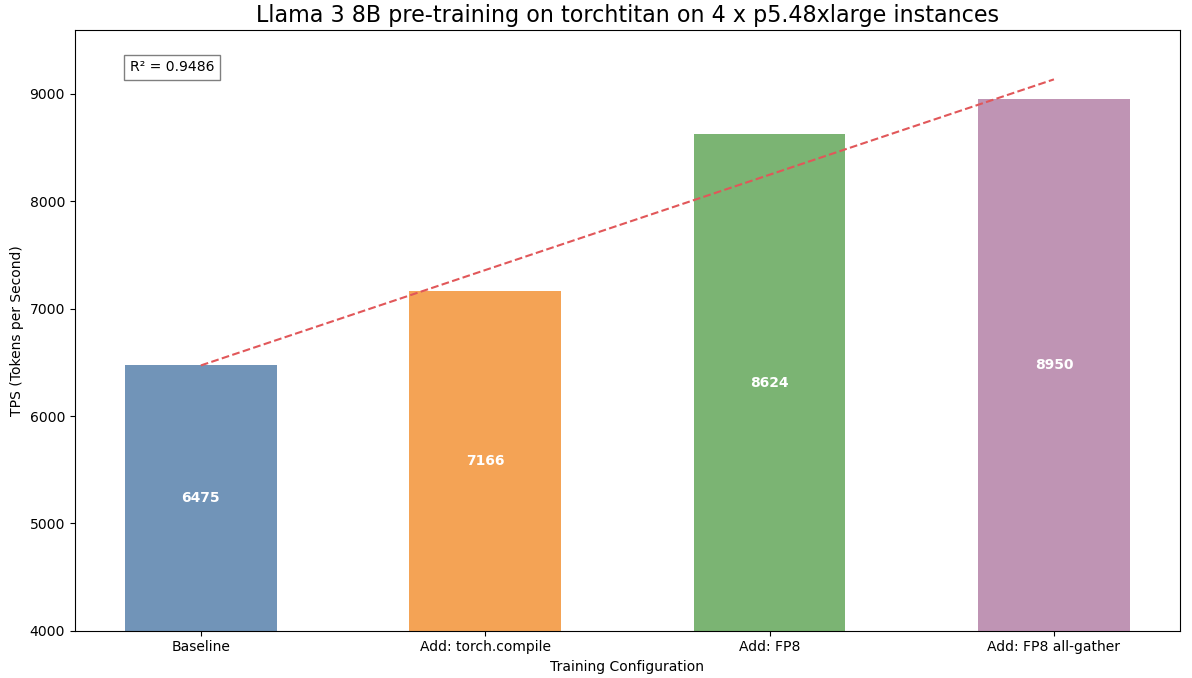
Performance numbers
The following table summarizes the performance numbers for the various training runs with different optimizations.
Setup
Configuration
TOML Configuration
Throughput
(Tokens per Second)
Speedup Over
Baseline
LLama3 – 8B pre-training on 4 x p5.48xlarge instances
(32 NVIDIA H100 GPUs)
Baseline
Default Configuration
6475
–
torch.compile
compile = true
7166
10.67%
FP8 linear
compile = true
enable_float8_linear = true
8624
33.19%
FP8 all-gather
compile = true
enable_float8_linear = true
enable_fsdp_float8_all_gather= true
precompute_float8_dynamic_scale_for_fsdp = true
8950
38.23%
The performance results show clear optimization progress in Meta Llama 3 8B pre-training. torch.compile() delivered an 10.67% speedup, and FP8 linear operations tripled this to 33%. Adding FP8 all-gather further increased the speedup to 38.23% over the baseline. This progression demonstrates how combining optimization strategies significantly enhances training efficiency.
The following figure illustrates the stepwise performance gains for Meta Llama 3 8B pre-training on torchtitan with the optimizations.
These optimizations didn’t affect the model’s training quality. The loss curves for all optimization levels, including the baseline, torch.compile(), FP8 linear, and FP8 all-gather configurations, remained consistent throughout the training process, as shown in the following figure.
The following table showcases the consistent loss value with the different configurations.
Configuration
Loss After 2,000 Steps
Baseline
3.602
Plus torch.compile
3.601
Plus FP8
3.612
Plus FP8 all-gather
3.607
Clean up
After you complete your training experiments, clean up your resources to avoid unnecessary charges. You can start by deleting any unused SageMaker Studio resources. Next, remove the custom container image from Amazon ECR by deleting the repository you created. If you ran the optional step to use your own dataset, delete the S3 bucket where this data was stored.
Conclusion
In this post, we demonstrated how to efficiently pre-train Meta Llama 3 models using the torchtitan library on SageMaker. With torchtitan’s advanced optimizations, including torch.compile, FP8 linear operations, and FP8 all-gather, we achieved a 38.23% acceleration in Meta Llama 3 8B pre-training without compromising the model’s accuracy.
SageMaker simplified the large-scale training by offering seamless integration with custom containers, effortless scaling across multiple instances, built-in support for distributed training, and integration with TensorBoard for real-time monitoring.
Pre-training is a crucial step in developing powerful and adaptable LLMs that can effectively tackle a wide range of tasks and applications. By combining the latest PyTorch distributed training features in torchtitan with the scalability and flexibility of SageMaker, organizations can use their proprietary data and domain expertise to create robust and high-performance AI models. Get started by visiting the GitHub repository for the complete code example and optimize your LLM pre-training workflow.
Special thanks
Special thanks to Gokul Nadathur (Engineering Manager at Meta), Gal Oshri (Principal Product Manager Technical at AWS) and Janosch Woschitz (Sr. ML Solution Architect at AWS) for their support to the launch of this post.
About the Authors
Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS.He helps AWS customers—from small startups to large enterprises—train and deploy foundation models efficiently on AWS. He is passionate about computational optimization problems and improving the performance of AI workloads.
Kanwaljit Khurmi is a Principal Solutions Architect at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS. Kanwaljit specializes in helping customers with containerized and machine learning applications.
Trevor Harvey is a Principal Specialist in Generative AI at Amazon Web Services (AWS) and an AWS Certified Solutions Architect – Professional. He serves as a voting member of the PyTorch Foundation Governing Board, where he contributes to the strategic advancement of open-source deep learning frameworks. At AWS, Trevor works with customers to design and implement machine learning solutions and leads go-to-market strategies for generative AI services.
Less Wright is an AI/Partner Engineer in PyTorch. He works on Triton/CUDA kernels (Accelerating Dequant with SplitK work decomposition); paged, streaming, and quantized optimizers; and PyTorch Distributed (PyTorch FSDP).
Wei Feng is a Software Engineer on the PyTorch distributed team. He has worked on float8 all-gather for FSDP2, TP (Tensor Parallel) in TorchTitan, and 4-bit quantization for distributed QLoRA in TorchTune. He is also a core maintainer of FSDP2.
In this post, we collaborate with the team working on PyTorch at Meta to showcase how the torchtitan library accelerates and simplifies the pre-training of Meta Llama 3-like model architectures. We showcase the key features and capabilities of torchtitan such as FSDP2, torch.compile integration, and FP8 support that optimize the training efficiency. Read More